给一个无状态 AI 装上「记忆衰减警报」—— Archon 漂移机制的设计原理
本文解释 Archon 框架里 drift(认知漂移)与周期性评审机制的设计动机、运行原理以及实际解决的问题边界(与局限)。
读者:想理解漂移为何存在、它的分级阈值如何运作的人 —— 不只是想知道日常怎么操作。要看交付内部实际跑的形态,去读 architecture.md §知识演进系统 与
{platform}/commands/archon-demand.md里的 wake/close-out 流。
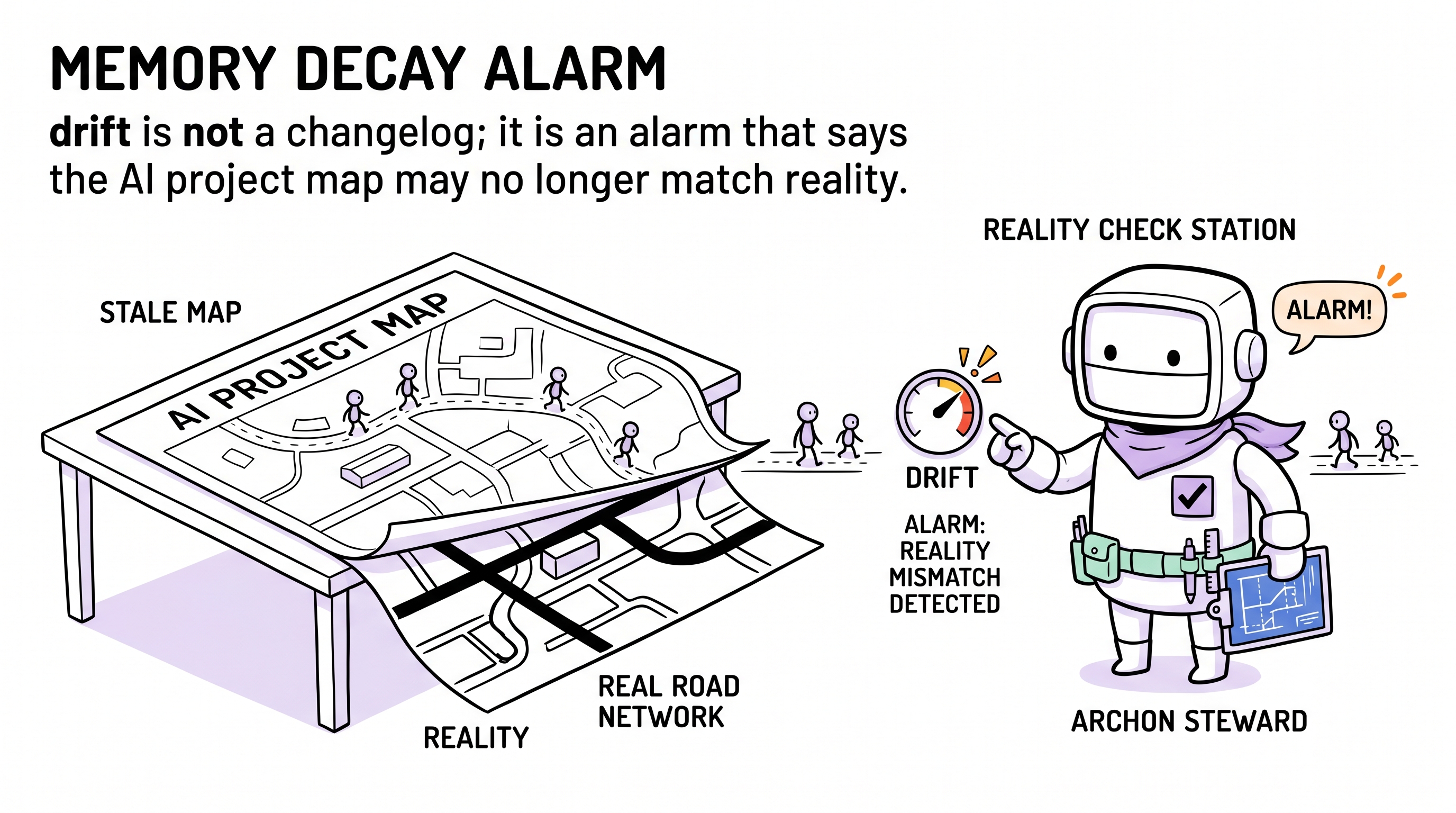
漂移是 Archon 的记忆衰减警报:它不复制 Git 历史;它告诉代理 —— 你脑里的项目地图可能已经不可信到不能再蒙头交付的程度。
一个你也许没注意到的问题
你和 AI 结对编程一下午。它加了三个特性、重构了数据层、引入了一个新库。第二天早上一个新会话读了项目文件,仍然用着重构前的旧模式 —— 因为它对昨天的事没有亲历记忆。
这不是 bug。这是 LLM 会话的根本现实:每个会话都从一张白纸开始。
聪明做法是把项目状态写进文件 —— manifest、规格文档、规则文件 —— 让 AI 每次 boot 加载它们。但这造出一个更隐蔽的问题:
谁来确保那些文件本身没过期?
你连续交付十次,每次都改代码,但 manifest 只更新过六次。规则文件还在描述昨天的架构。Skill 例子也许已经无法编译。AI 读到的"项目真相"和项目实际状态之间,有一道越来越宽的缝。
那道缝就是漂移。
漂移不是「变更日志」
先纠正一个常见误解:漂移不跟踪"哪些文件改了"。Git 已经做这件事了,而且做得比任何 markdown 文件都好。
漂移跟踪的是:AI 认知模型偏离项目现实的速率。
想象你有一张地图。每次走一条新路,地图都不更新。一两条还行 —— 你记得。十条之后你开始迷路。问题不是"十条路没画"—— 问题是"这张地图你还该信几分?"
漂移计数器就是那个信任度的反向。它不告诉你哪里错了 —— 它告诉你:该停下来,重新看一眼全景了。
量化
每次交付后,主代理评估这次改动的认知影响:
| 复杂度 | 含义 | 分数 |
|---|---|---|
| trivial | 单文件改动、配置调整 | +1 |
| small | 2-5 个文件,无新模式 | +2 |
| medium | 新模块、新模式,5-10 个文件 | +3 |
| large | 架构改动、跨层修改 | +5 |
注意:评估的是认知复杂度,不是 diff 行数。一个三行的 API 签名改动如果影响十个调用方,认知影响远大于一个五十行的新组件。
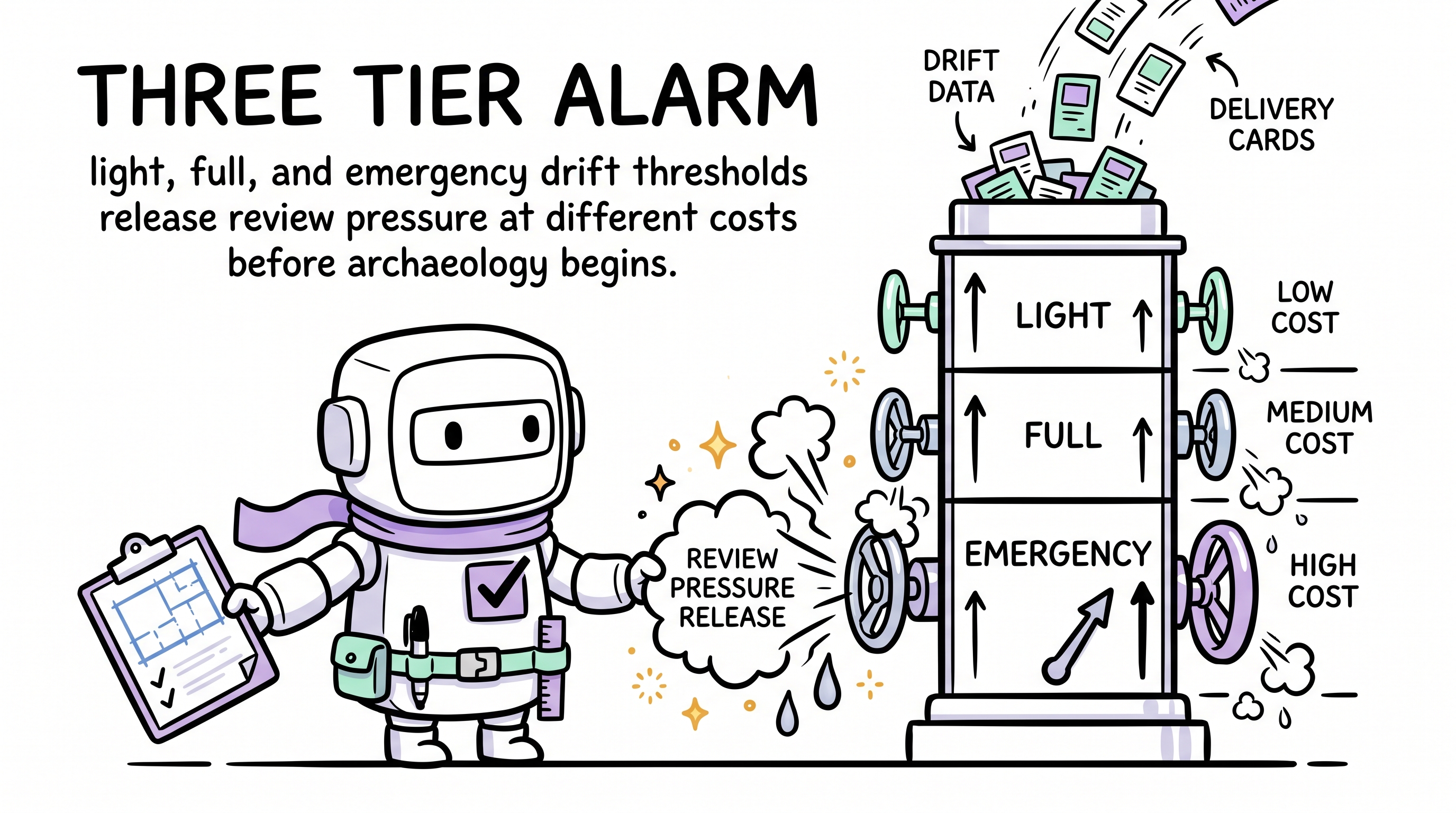
阈值分级。三个门(light / full / emergency)以不同节奏释放压力,替代原先单门二元触发 —— 后者在真实负载下已被证明会失效(见 ADR-9)。
| 级别 | 默认阈值 | 发生什么 |
|---|---|---|
| Light | 6 | 仅做机械健康审计(≤完整评审成本的 10%)· 释放 2-4 分 · 下次 medium/large 需求等它跑完 |
| Full | 12 | Reviewer 子代理 + 完整四阶段审计 · 重置到 0-3 |
| Emergency | 20 | 暂停需求接入 · 完整评审 + 盲区根因 + 强制整改计划 |
默认数值是从五次真实评审周期里观察校准的。太低会在密集构建期频繁打断;太高会让每次评审变成考古。阈值还会按项目阶段动态调 —— 构建密集期容忍更高漂移;质量收敛期收紧。在被声明为收敛期时,emergency 阈值从 20 收紧到 14,因为框架演进的噪声此时正在把交付从有界债务上拉走。见 drift.md §评审分级 与 ADR-12。
机械保底(在为每次交付打分时应用):自评分受 max(self_assessment, floor) 下界约束。≥3 个文件 → +2;≥6 个文件 → +3;≥10 个文件 或 新模块/新模式 → +5。保底存在是因为自评经验上向 +1/+2 "诚实低估"偏倚。见 drift.md §规则。
存储形态 —— 一事件一文件(ADR-22)
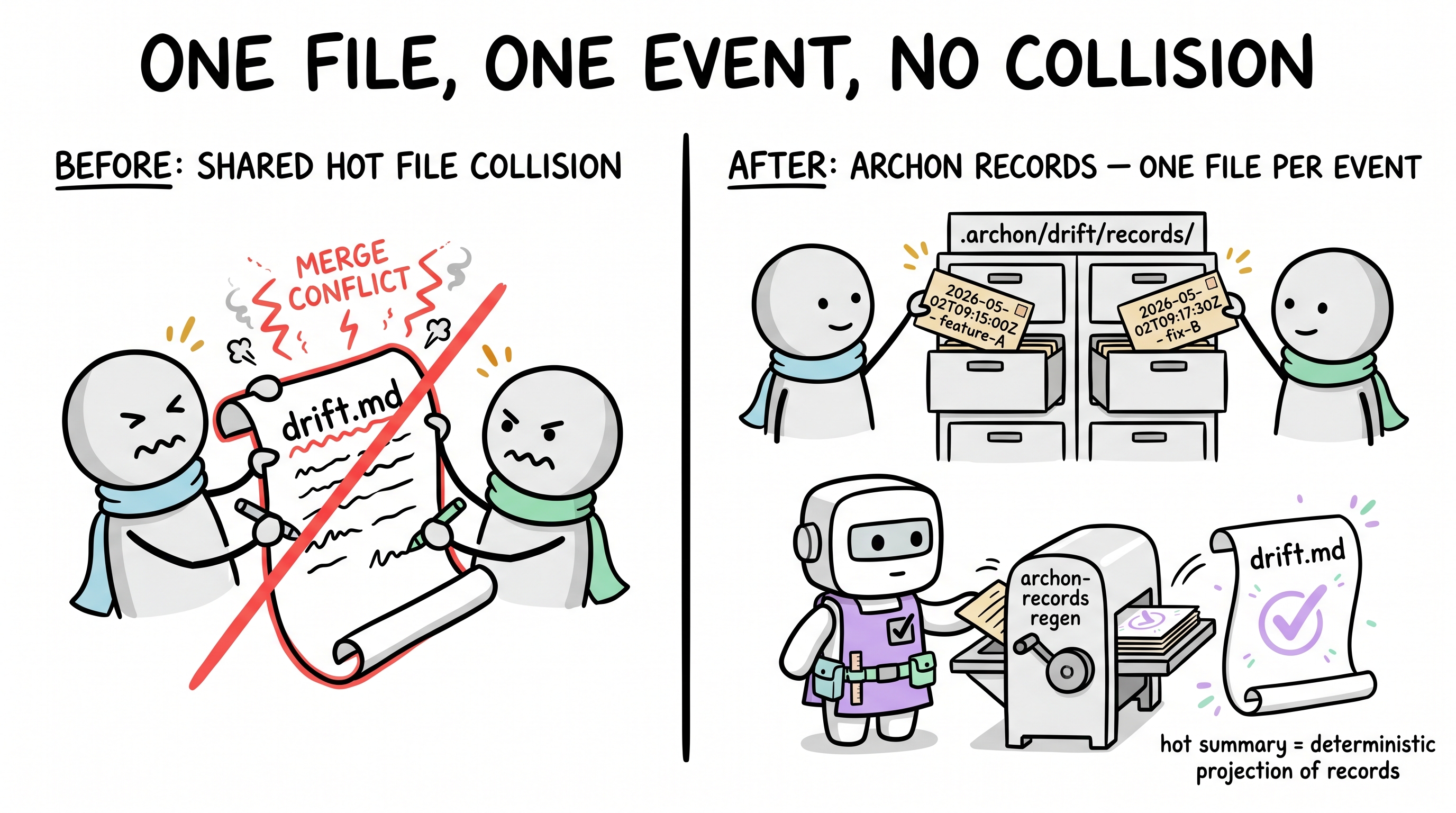
本文档早期版本把 drift.md 描述为单个 append-only 热文件。这个心智模型对读仍然成立 —— 热摘要是代理首先看的地方。但写一个共享 append-only 文件,在并发的云代理交付下会塌:两个分支同时 append,必然产生无法机械解决的合并冲突。
按 ADR-22,存储形态切到了事件溯源。每次完成的交付、备忘或债务项都成为自己一个不可变的记录文件,存于 .archon/drift/records/<ISO8601>-<slug>.md(memos 与 debt 有平行目录)。热摘要(drift.md / memos.md / debt.md)由 scripts/archon-records.mjs 重新生成;在哨兵之间手改热摘要会让校验失败。漂移计数器变成对 records 的可交换求和 —— 平行分支可以独立写 +5 与 -3,合并后仍收敛到同一总和,无需手动重排序号。
ADR-21 的渐进加载纪律(热索引 + 冷归档)保留:热摘要仍是单次快读、records 目录仍不在热路径、季度折叠归档仍以 merge=union 折叠。唯一变的是热文件如今是投影,不是真相源。快照状态(manifest §当前状态、§收敛范围、§最近评审)有意保持在 records 之外 —— 那些是"此刻为真"的事,平行编辑就是真实的语义冲突,需要人来解决,不该被 CRDT 化。
并发有两面。 Records-folder 解决治理状态这一面:两个分支可以各自往自己的漂移记录里加 +5 / -3,最终仍收敛。ADR-29 的 源码模块化探针 在 Decision Gate 处解决源码这一面:当一个新文件、或一条已映射的路径会让一个已经承担一条概念轴的文件折入第二条轴时,探针在写下任何代码之前闪烁 fan-out-needed,提示先做一次拆分提交、或显式更新 map。两者合在一起,既消除了「事件追加冲突」(存储侧),也消除了「两个需求改同一文件」的冲突(创作侧)。这两个探针都不阻塞 Verdict —— 它们让结构事实可见,让所有者的覆盖决定带上明确理由。
为什么是三级,不是一级?
二元门的病理:在密集构建期,唯一一次穿越被推迟(漂移持续上涨,评审变成考古);在安静期,连微小的累积也付出完整评审的代价。Light 评审解决前者;fast-path(见 soul/delivery.md §交付快路径)解决后者。
emergency 级别存在是因为:即使一个设计正确的完整评审门,如果只在 L3(文档)层强制,也会失效。历史证明过:漂移到达完整阈值的 108% 时,需求仍在执行。emergency 级别就是那条断路器 —— 而 ADR-9 把预检本身从 L3 提升到 L1(governance.test.ts)以防复发。
评审不是「跑一遍清单」
这是最容易做错的部分。
如果评审就是"打开每个文件、对清单打勾",那它真的就是浪费时间。你花了 token 和时间,换来一句"全都符合"的虚假安慰。
Archon 的评审分两层运作,解决不同的问题。
第一层:自动化能做的,不要手工做
验证门先跑 lint + typecheck + test。机器能抓的问题(类型不匹配、未使用 import、失败的测试),永远不该出现在手工评审报告里 —— 它们应该在你写代码时就被抓。
如果你的评审报告满是"这个变量没用上"或"那个类型不对",说明你的自动化工具链有缺口 —— 不是说你的评审更彻底。
第二层:人(或独立代理)做的事,是自动化做不到的
评审里真正有价值的部分,是自动化无法从单个改动文件推断出来的:
- 架构腐化:模块间依赖是不是悄悄变成意大利面?
- 抽象是否合理:是否存在只有一个实现的抽象层?是否有 "utils" 文件膨胀成杂物抽屉?
- 规格漂移:代码实际做的,还和 manifest/规格文件声明的对齐吗?
- 停滞检测:最近五次交付是否都在修同类问题?如果是 —— 单个修复都没用,需要根因分析。
最后一点尤其重要。读漂移日志不是为了知道"发生了什么"—— 是为了发现模式。同类修复反复出现 = 一个没人在解决的系统性问题。日志记录症状;评审的工作是从症状里诊断病。
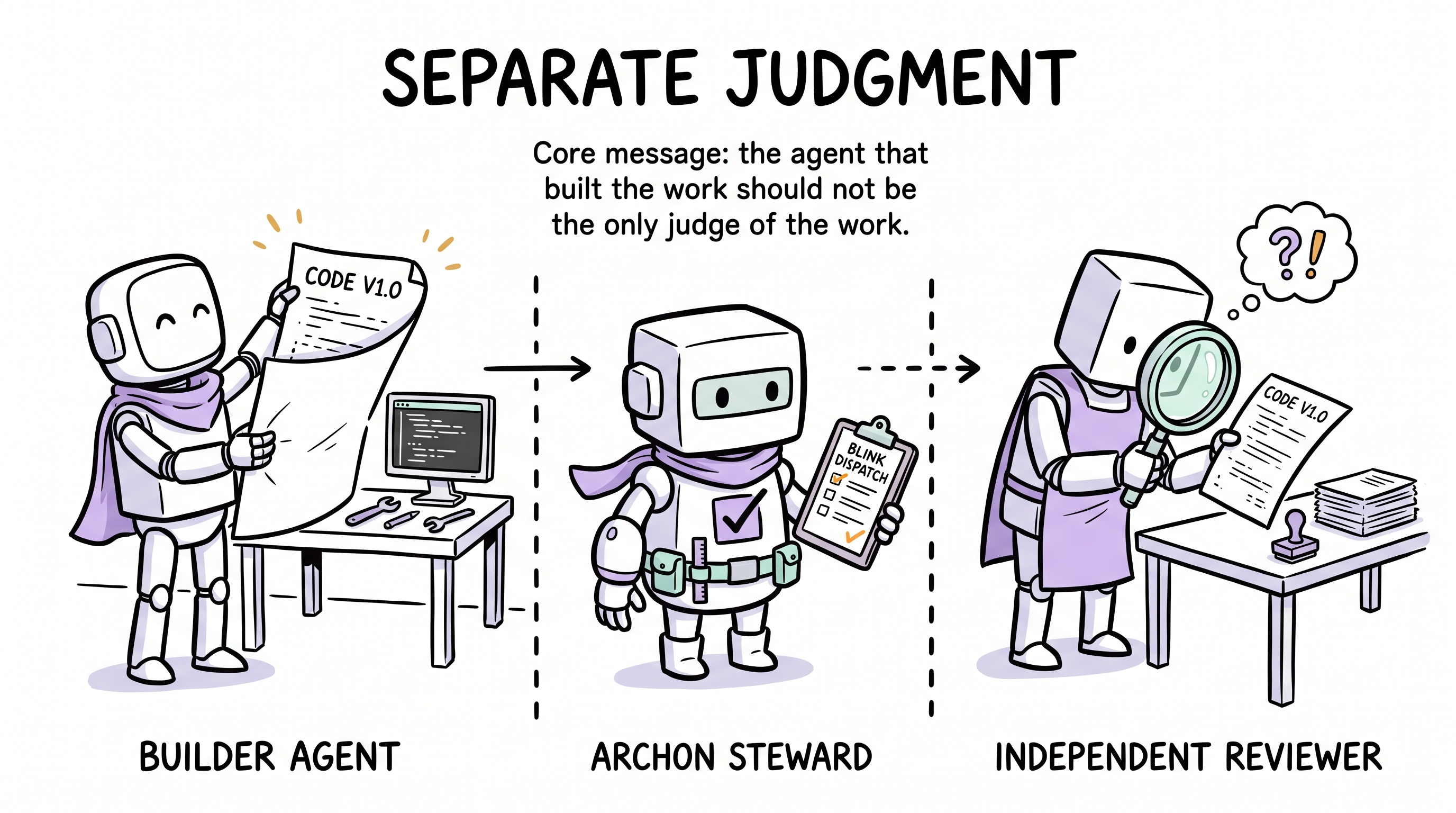
为什么评审必须是独立子代理
这是整个机制里最反直觉、却最关键的设计决定。
你写了一天代码,然后审自己的代码。能找到什么?几乎肯定什么都找不到。不是因为代码真的好,而是因为沉没成本偏差 —— 你的脑子会自动为刚刚重金投入的产物找合理化解释。
人类工程师如此,LLM 也一样。在同一个上下文窗口内,刚生成代码的代理在评审自己产出时天然倾向"看着不错"。
Archon 的解法是执行与判断的条件性分离:
- 主代理写代码
- 在任何子代理启动前,Blink Dispatch 对完成的 diff 做薄切判定
- 当漂移达到完整评审阈值时,独立 reviewer 子代理来评 —— 它没写过这段代码、没有沉没成本、没有合理化动机
- 当 Blink Dispatch 检测到实现、治理、边界、修复、状态闭合或不确定性风险时,独立 capture-auditor 子代理评估交付后的知识捕获
每多一个子代理就多一次 LLM 调用的延迟与成本。所以并不是每一步都需要独立判断 —— 只有满足以下任一条件的才需要:
- 判断发生在工作完成之后(沉没成本偏差最强)
- 判断没有自纠正机制(错了没人抓)
- 错误成本高(影响正确性或架构健康)
其余继续走自评。要节制。
知识捕获:不是「每次都记点东西」

Archon 的另一个子机制是交付后知识捕获 —— Blink Dispatch 先决定本次交付是否值得做独立捕获评审,capture-auditor 再判定它是否产生了值得结晶的知识。
关键词是「值得」。
如果每次交付后都记点什么,你会很快堆出一堆没人读的"经验笔记"。知识膨胀比知识缺口更危险:前者给人「自以为知道」的错觉,后者至少诚实。
捕获触发是具体的:
- 撞墙转向:方案 A 失败,切到 B。值得记下的不是"选了 B",而是 A 的失败症状 → 根因 → B 的推导路径 —— 下次再遇同样症状时复用已验证路径,而不是重新推一遍。
- 重复模式:第二次写出同一种结构。该抽象,不是该写文档。
- 概念被发现:出现一个项目特异术语,按它的字典常义会被误读。把它捕获进 manifest 词汇表 —— 下次会话 AI 启动时就带着正确的语义框架,而不是去猜。
- 干系人别名浮现:干系人反复用某个短语、昵称或间接描述("那个覆面卡"、"门户页")指向已定义的工件。把它捕获进 用户语言索引(User Language Index),而不是词汇表 —— 索引把措辞映射到规范目标(路由、文件、组件),
/archon-demand §Pre-Scan在每次需求时查询它,让代理不必猜、用户也不必重述。

- 约定结晶:一条隐式约定在代码里反复出现。是时候让它变成机器可执行规则,不是文档。
而且捕获有优先级。能推到类型系统的,就别做 lint 规则;能做 lint 规则的,就别写文档;文档只承载「为什么」—— 这就是约束金字塔,越底层强制越强、被遗忘概率越低。
保留:演进的第二种运动(ADR-28)
捕获 —— 无论来自漂移信号、知识撞墙还是 reviewer 发现 —— 只是演进该做的一半。另一半是保留:主动保护已经在工作的东西,让它不能被悄悄改没。
只纠错的演进有一种特定失败模式。每个新周期都在追加修最近一次失败的规则。那些防住你从没看见的失败的规则 —— 那些解释为什么别处没坏的规则 —— 完全靠代理记忆。它们没有机械锚点。一次貌似合理的重构就能悄悄把它们抽走。触发表无法触发,因为没有可观察的失败。
按 ADR-28,保留是结晶的对偶:
- 结晶问:"本次交付教会了什么、应该改变 Archon?" → 提升到更强的载体(测试、规则、skill、ADR)。
- 保留问:"本次交付依赖了什么、绝不能被悄悄抽干?" → 用机械三件套钉死承重锚点:关键规则注册表的一条记录、一个体型测试、一条可移植契约条款。
Close-Out 的交付后评审现在两个问题都问。保留答案是以下之一:
preservation: pinned(<anchor>+<test>+<contract>)—— 本次交付用三件机械守卫钉住了一个具体的承重锚点。preservation: none-this-cycle(<evidence>)—— 本次交付扫过承重锚点,没找到值得钉的。证据必须命名扫描目标与动作(如"扫了 soul §Imperatives 的 12 行,全部已钉")。
保留钉是绊线,不是墙。你仍然可以移除一条已钉规则 —— 但移除必须显式(同时删掉锚点、测试、契约条目),不能是默默抽干内容。这恰恰就是「演进」与「向最近一次修复漂移」的区别。
演进节奏:不要模式开关,要从状态推断
一种常见诱惑是给系统加"模式" —— mode=build 用来赶特性、mode=harden 用来加固质量。
这行不通。原因很简单:谁负责切换模式?
如果 AI 来定,它会永远停在 "build" 模式 —— 因为待办永远做不完。如果用户手动切,用户得知道何时该加固,这违反"不要让用户做工程决策"。
Archon 的方法是从项目状态推断行为:
- 里程碑早期、多数验收准则未勾选 → 偏向特性交付
- 特性已完成、质量门红 → 偏向加固
- 债务登记簿有 Critical/Warning 临近 deadline → 偏向修复
- 最近 5 条漂移记录里 ≥3 条是同类修复 → 停滞信号 —— 需要根因分析
不要配置、不要开关。信号已经在 manifest 与漂移日志里 —— 读它们,不要再加一层抽象。
老实说,这个机制不解决什么
任何只讲优势的设计文章都不诚实。坦率地:漂移机制有根本性的局限。
1. 它不能替代架构思考。
漂移 + 评审能发现"这里不对",但发现不了"系统整体该怎么设计"。评审是诊断,不是规划。你不能指望周期性检查替代深入的架构思考 —— 那要靠 plan 模式的刻意探索,不是 review 模式的合规检查。
2. 量化是粗糙的。
"medium = +3"?谁说的?引入一种新状态管理模式的 medium 交付,和一个 medium 的纯 UI 交付,认知影响完全不同。分数是对复杂度的粗略近似 —— 它的价值在于"该停下来看看四周"这个信号本身,而不是具体数字。
3. 评审质量取决于评审者能力。
reviewer 是一个 LLM 子代理。它的评审深度受限于上下文窗口能容纳的代码量与它的推理能力。对几十文件的小项目它能做全面检查。但项目规模上来后,"完整评审"要么变成表面扫描、要么需要按模块分解 —— 那条演进路径还没实现。
4. 知识捕获里"是否值得"的判断本身就难。
capture-auditor 是独立、轻量、由快模型驱动的。它能查"是否有新测试文件"、"是否有重复模式"。但"这次交付的洞见是否有长期复用价值" —— 这个判断需要对项目历史与技术选择的深理解,轻量子代理很吃力。实践中大部分交付的捕获结果是 —(什么都没捕到)。这个比例是否合适,仍是一个开放问题。
那它到底解决什么?
剥掉机制细节,漂移 + 评审解决的核心问题只有一个:
在基于会话的 AI 工程环境里,造出一个强迫你停下来看全景的节奏。
人类工程师有 code review、站会、retro 来做这件事。AI 代理没同事、没日历、没"哪儿不对劲"的本能。它需要一个外部化、量化、不可跳过的触发,来打破"接需求 → 写代码 → 接需求 → 写代码"的死循环。
漂移就是那个触发。仅此而已,不多不少。
它不保证评审高质量 —— 那靠 reviewer 协议设计与 LLM 推理能力。 它不保证知识捕获正确 —— 那靠 auditor 判断与结晶路径设计。 它不保证架构不腐化 —— 架构健康靠主动规划与深思考,不靠被动周期性检查。
它精确保证一件事:你不会在认知已经严重偏离现实时仍在蒙头交付。
那一件事,已经足够重要了。
本文是 Archon 工程治理框架设计笔记系列的一部分。Archon 是一个跑在 AI 结对编程 IDE 内、基于会话的 AI 工程治理框架。