用户旅程:你绝对踩过的那些坑
下面的每一段旅程都是 AI 辅助编码中真实发生过的事。 如果你用 AI 写代码超过一周,下面至少有三条你亲身经历过。
这些旅程是从重复出现的 AI 辅助交付失败中提炼出来的。每个模式必须出现不止一次,Archon 才会把它变成更强的机制。
延伸阅读:Model vs. Harness —— 为什么这些问题不会随着模型变强而消失(它们是环境问题,不是推理问题)。
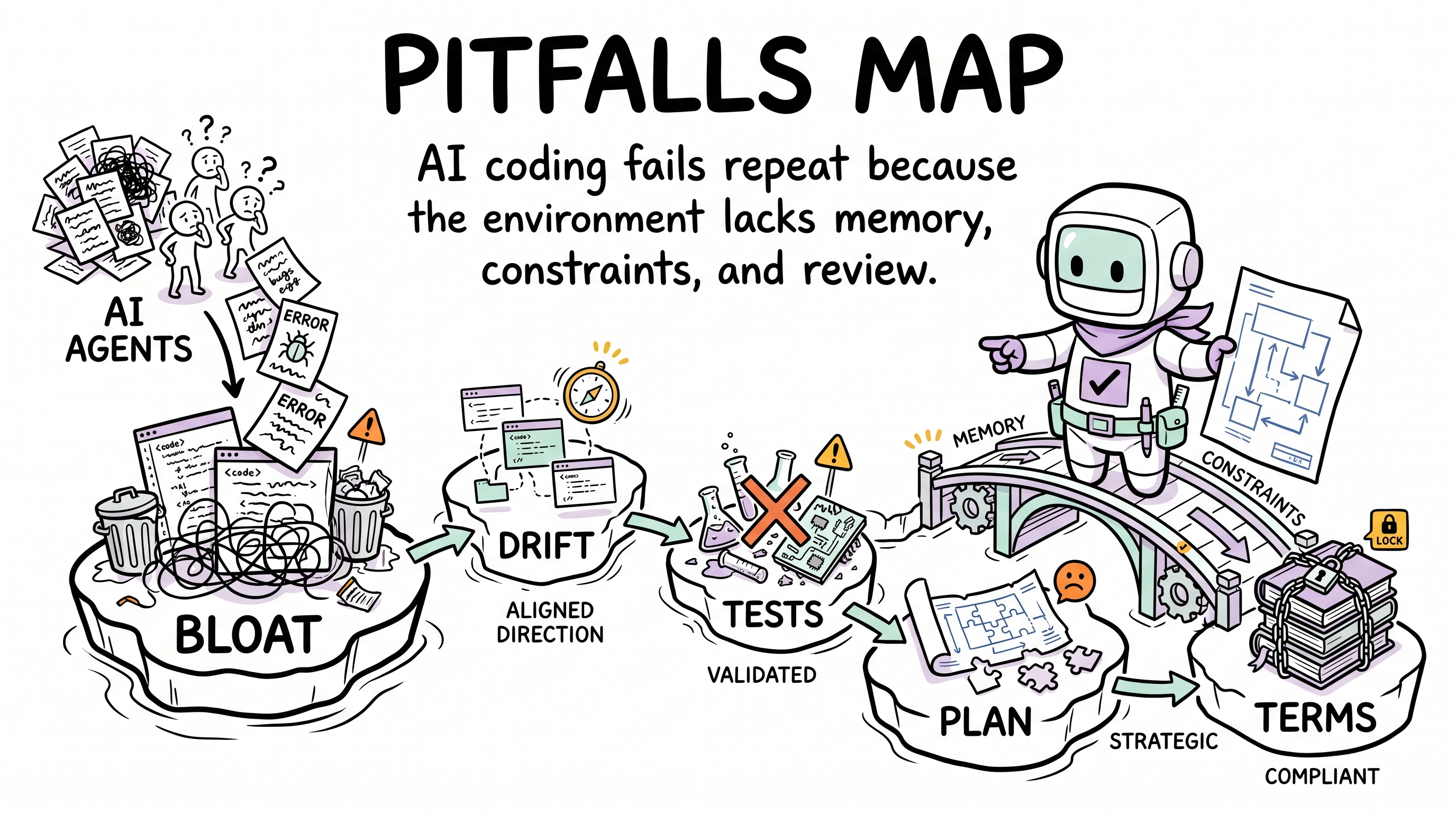
按四个机制聚类来读:记忆漂移、质量护栏、规划/架构、知识对齐。每段旅程保留具体失败故事,漫画图先在细节之前给出机制模式。
聚类 1:漂移、记忆与模式健康
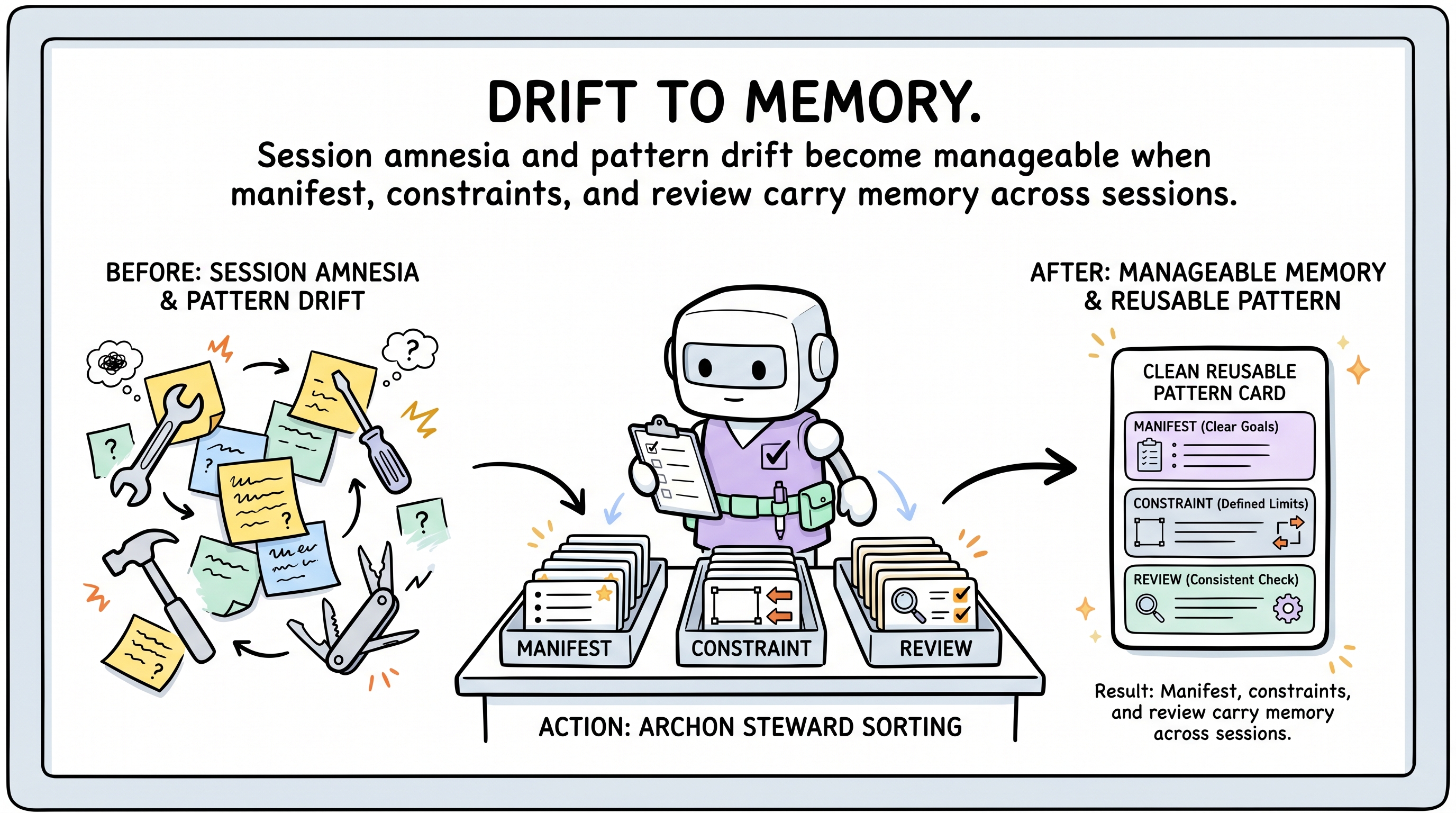
前面这些旅程都是同一个失败的不同版本:AI 为当前请求做局部最优,丢掉了之前会话留下的压力。Archon 把那种压力转换成 manifest 记忆、评审发现与约束。
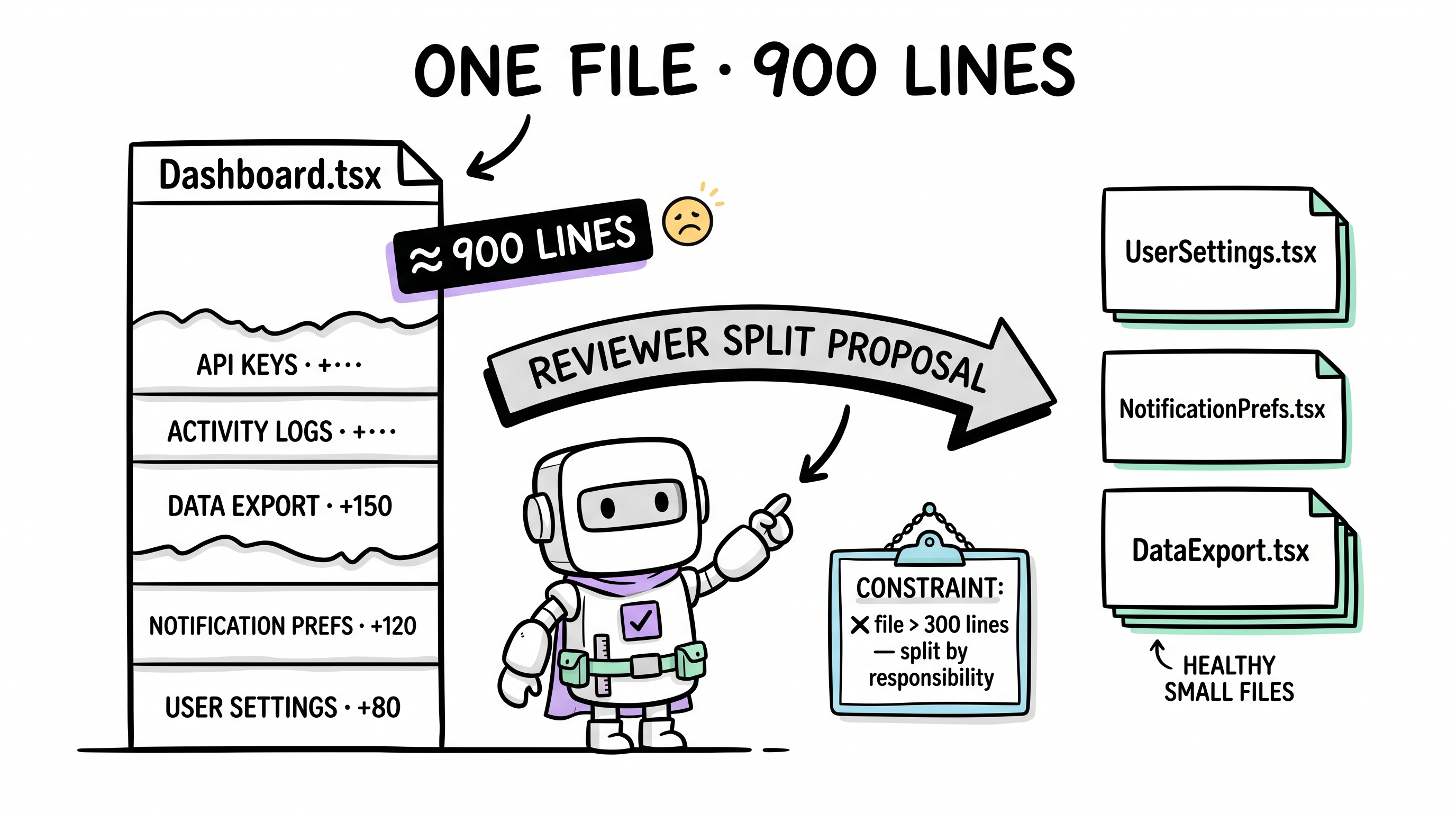
旅程 1:永不停止膨胀的文件
你:「给 Dashboard 加用户设置。」
AI 加了 80 行。文件现在 280 行。没问题。
你:「把通知偏好也加上。」
AI 又加 120 行。400 行。还行。
你:「再加数据导出功能。」
又 150 行。550 行。然后是活动日志。然后是 API key 管理。文件现在 900 行。 没有任何人类开发者会让一个文件膨胀到这个尺寸 —— 他们会本能地在 ~300 行左右拆分。但 AI 没那个本能。它对「太大了」没记忆。它优化的是「完成当前请求」,不是「保持代码库健康」。
Archon 怎么处理
Reviewer 子代理 在结构性审计期间主动检测文件膨胀。当文件越过阈值时:
- 标记膨胀 —— 「这个文件有 5 个职责;按关注点分离来拆」
- 提出具体拆分方案 ——
UserSettings.tsx、NotificationPrefs.tsx、DataExport.tsx - 后续约束 —— 一条约束被结晶:
❌ 文件超过 300 行 —— 按职责边界拆分
文件不会无声膨胀。系统捕捉并行动。
旅程 2:同一概念,五种实现
第 1 周:AI 用 useState + useEffect 取数据。 第 2 周:AI 用 useSWR —— 它「学」到了更好的模式。 第 3 周:AI 选 RTK Query —— 项目里已经有 Redux。 第 4 周:又回到原始 fetch,包了一层工具函数。 第 5 周:自定义 hook 包 axios。
五种都能用。每种孤立看都还行。但代码到了 6 万行时,你有五种取数据范式,每个新开发者(人或 AI)都得猜哪个是「正确的」。
Archon 怎么处理
Archon 的约束系统在模式被建立后将其锁定。第一种取数据方式被选定并验证后,它变成约束:
约束示例:
❌ 在 API 调用中使用原始 fetch/axios —— 使用既定的 useSWR hook 模式
后续每次会话,这条约束在生成时被注入到 AI 的上下文窗口 —— 不是「待会读的建议」,而是实时塑造代码输出的活规则。AI 不会漂到别的模式去,因为禁令是它指令集的一部分。
漂移检测也跨会话监控模式不一致,当代码库偏离已声明模式时触发评审。
旅程 3:跨会话失忆症
周一下午:你和 AI 花 2 小时重构 auth 模块。你抽出共享的 useAuth hook、合并 token 刷新逻辑、删掉三处冗余的 auth 检查。
周二早上:新的 chat 会话。你说「给设置页加基于角色的访问控制」。AI 写了一个全新的内联 auth 检查 —— 正是你昨天花时间消除的那种模式。它对昨天的重构毫无记忆。
Archon 怎么处理
Manifest 持久捕获项目级决策。周一重构后,manifest 记录:
- Auth 集中在
useAuthhook 中 - Token 刷新由
authProvider处理 - 内联 auth 检查被禁止
周二的会话把 manifest 加载进上下文。AI 看到既定模式并遵守 —— 不是因为它记得昨天,而是约束系统替它承载了记忆。
漂移检测对比 manifest 的「认知地图」与实际代码状态。如果 AI 的理解落后于现实,系统会在下一个任务开始前强制同步。
旅程 4:复制粘贴驱动开发
你:「给用户页加一个数据表格。」
AI 写 120 行:表格组件、排序、分页、搜索过滤。
你:「订单页加一个类似的表格。」
AI 把用户表格复制过去,改了列名。又 120 行,90% 重复。
你:「商品页也要一个。」
三份复制。它们几乎相同 —— 但排序逻辑、分页重置行为、搜索 debounce 时机各有微妙差异。当你修一个表格的 bug 时,另外两个还有这个 bug。
Archon 怎么处理
Soul 编码了三次法则:「两次重复不是抽象的理由 —— 过早泛化比重复更危险。」但第三次出现时系统触发:
- 模式识别 —— Reviewer 识别重复的表格模式
- 抽象提案 —— 抽出共享的
DataTable组件,含可配置的列定义、排序与分页 - 创建约束 ——
❌ 复制粘贴表格/列表 UI 模式 —— 使用共享的 DataTable 组件
从那一刻起,AI 用共享组件而不再复制。Bug 修复自动传播。
旅程 5:彩票式错误处理
A 页:API 出错 → 弹 toast 通知。 B 页:API 出错 → 在顶部渲染红色横幅。 C 页:API 出错 → 整个页面崩成白屏。
每页都在不同会话里写。每次 AI 都用「当时看起来在本地合理」的方式「处理了错误」。用户体验割裂:有时候错误优雅降级,有时候应用直接死掉。
Archon 怎么处理
这是知识演进系统在起作用。一个页面第一次因 API 失败而崩溃时,知识捕获循环结晶教训:
约束示例:
❌ 单一 API 失败拖崩整页 —— 用 isError/refetch 把每个区段独立包起来;❌ 错误展示模式不一致 —— 使用项目的 ErrorBoundary 组件。
它们变成永久约束。后续在 Archon 下构建的每个页面自动拥有:
- 每个 API 区段独立的 error boundary
- 通过既定模式统一的错误 UI
- 骨架加载态
第二个功能不重复第一个功能的错误。第十个功能几乎刀枪不入。
聚类 2:质量护栏
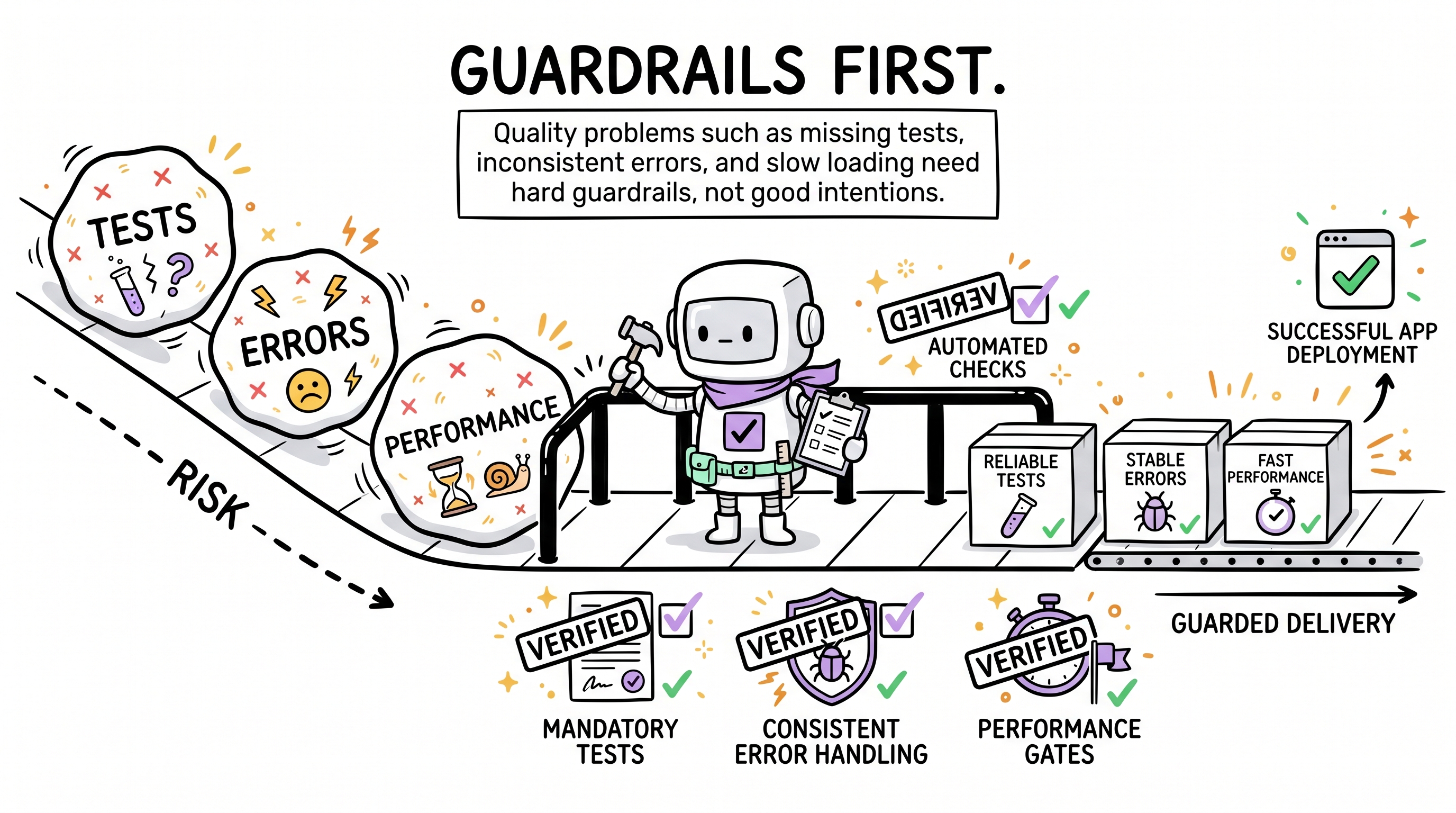
测试、加载态、错误边界、采纳 skill —— 这些不是可选润色。它们是阻止「本地能跑」变成「线上脆弱」的护栏。
旅程 6:测试?什么测试?

你让 AI 构建权限系统。它交付:角色定义、中间件守卫、路由保护、usePermission hook。它能跑。你合了。
然后你要 API key 系统。它交付:key 生成、校验中间件、管理端点。能跑。合了。
然后是雇佣生命周期系统。一共 16 个 API 端点,零行测试代码。
三个月后你改了一个共享工具函数的签名。哪些端点会坏?未知。你只能手动测每一个。
AI 把「能跑」当成「完工」。它感受不到改没测试代码的焦虑 —— 那是被烧过的人类本能。 结果:今天能跑、明天却无法安全修改的代码库。
Archon 怎么处理
这是 Archon 最痛的真实教训之一 —— 我们的 API 目录连续三个评审周期零测试覆盖,系统才捕捉并强制。
capture-auditor 子代理中的交付卫生检查标记未测试的新模块:
- 卫生标记 —— 「新模块
api/v1/api-keys.ts没有对应的测试文件」 - 债务登记 —— 如果一时修不掉,作为新的
.archon/debt/items/DEBT-NNN-<slug>.md文件登记,通过node scripts/archon-records.mjs new debt --id DEBT-NNN --severity ... --deadline ...(依 ADR-22;debt.md热索引自动重生) - 约束结晶 —— Soul 的「新代码 = 新护栏」原则:
新模块 → 测试文件同步出现 - 里程碑门 —— 里程碑关闭前,所有
milestone-closedeadline 的债务必须解决。无例外。
诚实备注:这条机制本身也迭代过。早期版本让交付者自评测试覆盖 —— 像让学生给自己的考卷打分。沉没成本偏差让代理一致地合理化「太简单不需要测试」。后来我们把这块拆到独立的 auditor 子代理,盲点才被修掉。
旅程 7:「我这台机器能跑」盲区
AI 构建了一个漂亮的仪表板。每个组件挂载时取数据。五个 API 调用同时发出。在你快速网络的开发机上,800ms 加载完。看起来很棒。
线上,移动网络的真实用户:页面加载 8 秒,数据陆续到达时布局跳动,慢连接用户看到 3 秒空白。
AI 从不考虑 happy path 之外的用户。它不想慢网络、不想大数据集、不想视口外内容、不想基于视口的加载。
Archon 怎么处理
AI 跳不过的架构约束:
约束示例:
❌ 不管滚动位置就发所有 API —— 使用 skip: !inView;❌ 异步区段没骨架/加载态 —— 数据前加 Skeleton;❌ 没有错误恢复 UI —— 失败请求加重试机制。
这些不是建议。它们是 AI 代码生成时活动指令集的一部分。AI 默认写视口感知、渐进加载、错误恢复的代码 —— 不是因为它聪明到能想到,而是约束系统不让它跳过。
旅程 8:新武器,没说明书
你让 AI 采纳一个新路由库。它读文档,写 20 个路由。下次会话,它用了更老的 API 风格。再下次会话,loader 模式跟前两次都不一样。
你采纳一个新的 serverless 运行时。AI 写 16 个 API 文件。每个对请求解析、认证、错误响应的处理都略有不同。没有「这个项目的 serverless 函数怎么写」的成文规范。
技术选型只是开始。 没有采纳规范 —— 推荐模式 + 禁用模式 + 迁移策略 —— 每次会话都是「从头学」。
Archon 怎么处理
Soul 的「新技术 = 同时交付一个采纳 skill」原则防住这个:
- 采纳 skill —— 引入新技术时,同时交付一个 skill 文档:推荐模式、禁用模式、从旧模式的迁移策略
- 结构守卫 —— Lint 规则阻挡旧模式(如
❌ 在 API 路由中直接 fetch —— 使用共享请求处理器) - 约束成熟度 —— 采纳 skill 起步是 SHOULD(文档),随模式稳定毕业为 MUST(lint 规则)
诚实备注:这条教训来自反复的框架采纳但没有配套 skill —— debt registry 在机制成型前在多个评审周期里标记同一模式。技术选型而无采纳计划是定时炸弹。
旅程 9:代码上线了,文档没有
你让 AI 构建权限系统。它交付:角色定义、中间件守卫、路由保护、usePermission hook。600 行代码,零行解释。你合了。
两周后,新队友问:「权限系统怎么工作的?有哪些角色?怎么加新的?」你找文档。没有。
你回去问 AI:「写一份权限系统文档。」它写了一个 README。但代码已经变了 —— README 一出生就过期。你让 AI 更新它。它用新版本覆盖旧版,少了上一版覆盖到的边界情况。
每个特性都重复这个循环。代码库在长,但文档要么缺、要么过期、要么自相矛盾。你做出了产品,但没人能逐行读源码以外读懂它。
Archon 怎么处理
Archon 把文档当成交付物,而不是事后想起的事。交付管线在多阶段强制:
Manifest 更新(Close-Out 第 1 步) —— 每个完成的特性记入项目 manifest:做了什么、在哪里、用了什么模式。这是项目的活目录。
知识演进 —— 当代理发现新模式或做架构决策时,它们被捕获到 skill 与架构决策记录 —— 不是留在某人 chat 历史里的部落知识。
漂移检测 —— 漂移机制跟踪文档是否反映现实。当代码改动跑得比文档更新快时,漂移计数器递增。到阈值时系统强制对齐:「manifest 说 auth 用 JWT,但代码已切换到 session token —— 更新 manifest。」
结构化交付记录 —— 每次重大改动产生一条结构化日志:改了什么、为什么、考虑过哪些替代以及为什么被拒。这是项目的机构记忆 —— 每个「what」背后的「why」。
最终结果:你的项目永远有一份当前、准确的自我地图。新成员(人或 AI)读 manifest 即可理解系统。无需考古。
聚类 3:规划、架构与性能
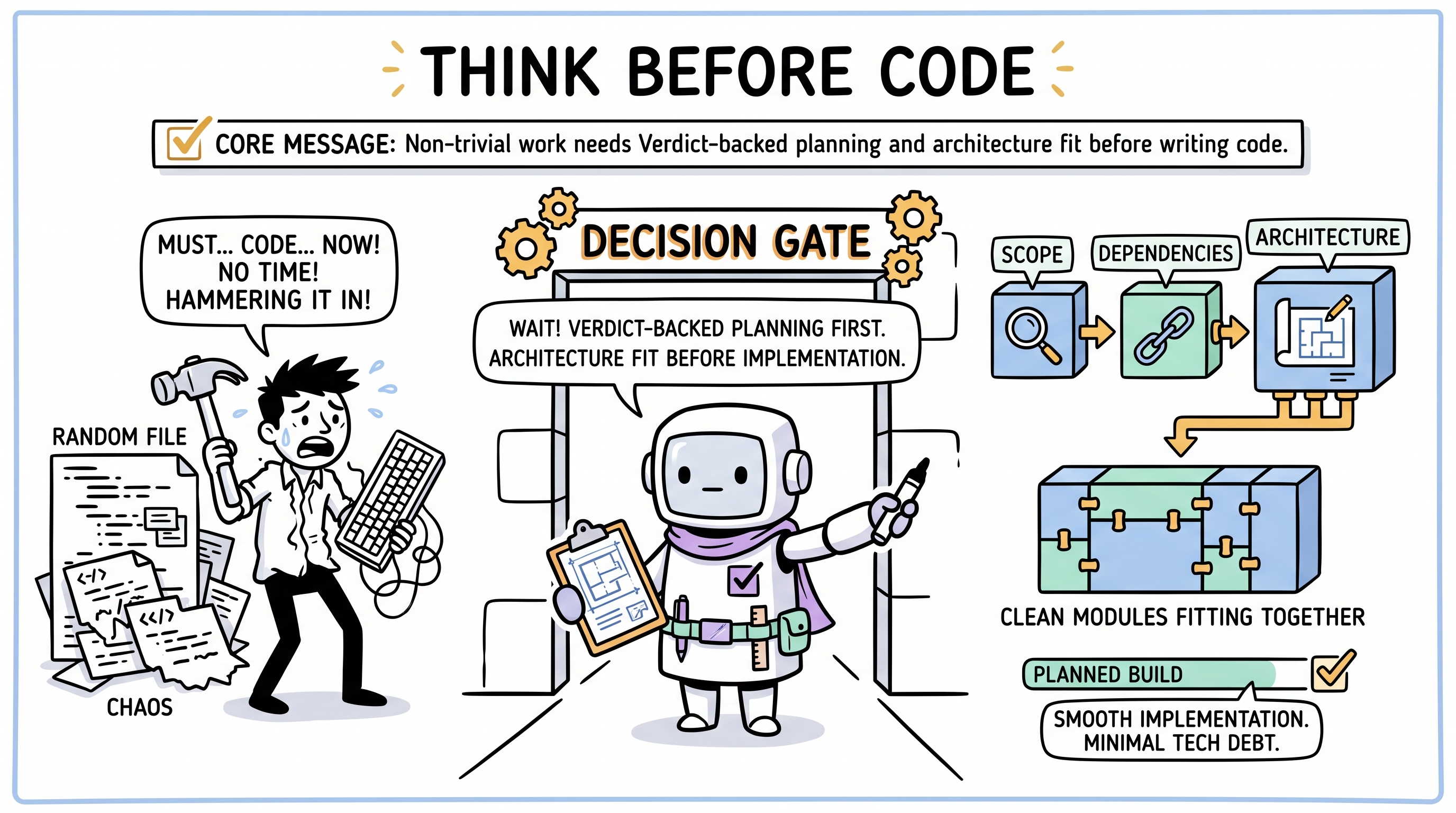
这些旅程覆盖了「过早写代码变得昂贵」的那个点。Archon 在局部修复硬化为架构债之前插入 Verdict 支撑的规划、子系统建模、连续评审。
旅程 10:「按我说的做就行」—— 规划是你的活

你:「加个通知系统。」
AI 立刻动手。它随手挑一个组件文件,开始写 <NotificationBell>,硬编码轮询间隔,在 useState 里存已读/未读状态,做了一个内联下拉。200 行后说「完工」。
你:「等等 —— 后端在哪?通知怎么生成?实时更新呢?持久化?分组?全标已读?」
AI 没规划。它听见「通知系统」就跳到第一个能渲染的具体东西。没有分解、没有范围评估、没有排序。 你现在有一个半成品 UI,没有后端、没有数据模型、也没有通往真实架构的迁移路径。
每个非平凡任务都会发生。AI 把「构建 X」当成「开始打字 X」。「理解需求」与「产出正确代码」之间的鸿沟 —— 那才是工程真正所在。
Archon 怎么处理
决策门 (Verdict)在任何代码写下之前触发。任务到达时:
- 爆炸半径评估 —— 触多少文件、模块、子系统?通知系统触:数据模型、API 层、实时传输、UI 组件、状态管理。这是多模块交付,不是单文件任务。
- 分解 —— 任务拆成有序的子交付:先 schema、再 API 端点、再实时订阅、再 UI、再集成测试。
- 依赖映射 —— UI 依赖 API;API 依赖 schema。代理在数据层存在前不会动 UI。
- 范围谈判 —— 如果任务对单次会话太大,Verdict 提议分阶段方案并请干系人确认范围。
结果:AI 不会「就开始打字」。它产出 Verdict 支撑的计划,然后通过自定向内部执行每个被接受的交付:代理选工具顺序、辅助代码与回退,而硬门仍保护范围、验证、Run-State 与评审。每个子交付独立可测。会话半途结束时,下一会话从计划接续 —— 不是从头来。
诚实备注:早期 Archon 版本没有 Verdict 门(当时叫
GATE-1)。代理就跟原版 AI 一样直接动手编码。我们在连续三次交付要求「撤销并按计划重来」之后加上了门 —— 返工成本是规划成本的 3 倍。
旅程 11:那个永远不出现的架构师
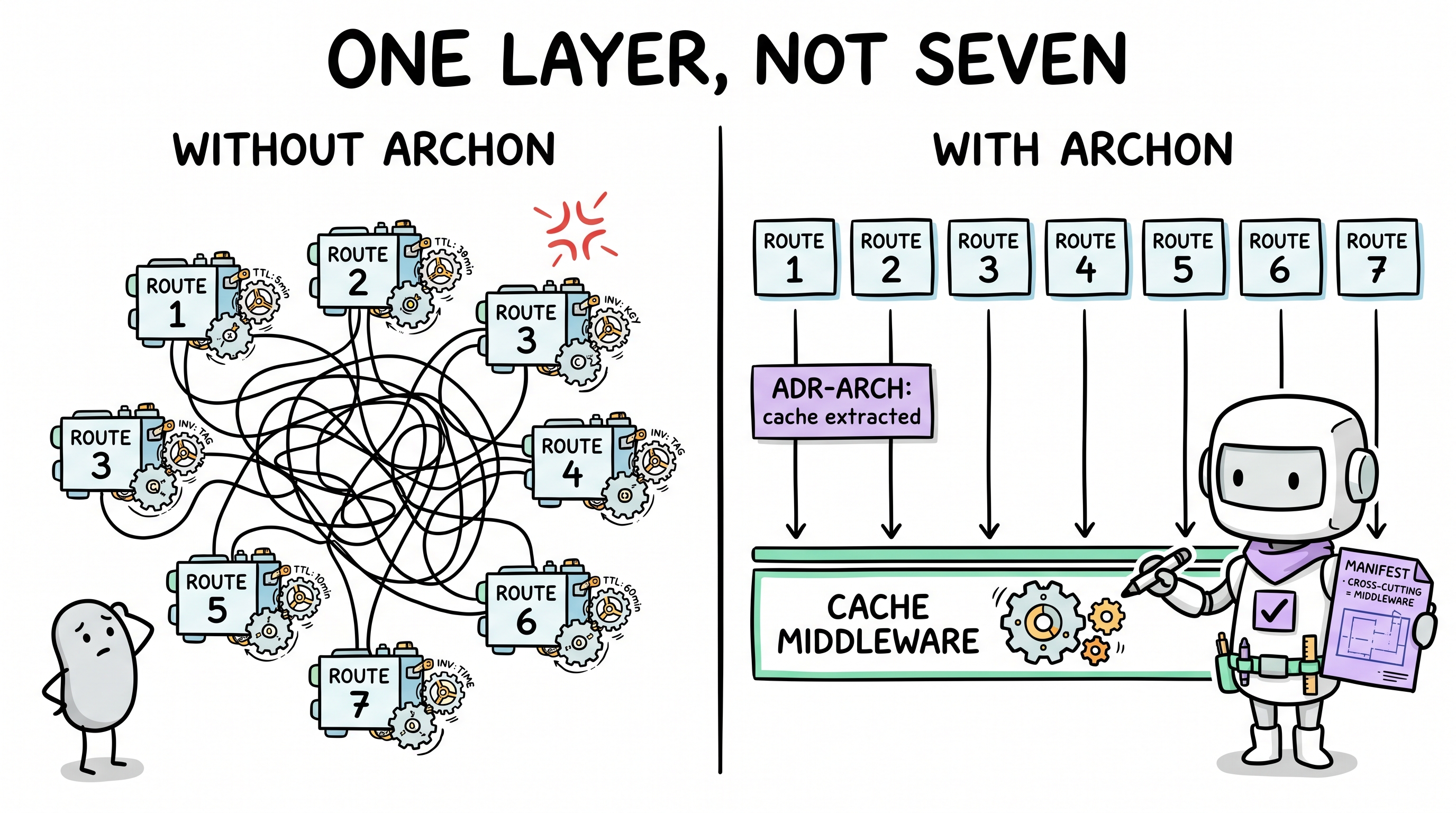
你让 AI 加一个缓存层。它把 node-cache 加到 API 路由处理器里 —— 就在数据库调用发生处内联。能跑。
下周你需要在另外三个端点上加缓存。AI 把 node-cache 各自独立加到每一个上。不同 TTL、不同失效策略、没有共享抽象。
一个月后,线上需要 Redis。每个端点都有自己定制的缓存逻辑。没有「缓存层」 —— 有 7 个独立的缓存实现。
AI 从不退一步问:「这里正确的架构边界是什么?」它从不提议:「在我把缓存加到第 2 个端点之前,让我把第 1 个端点的缓存抽到共享服务里。」它没有架构思维,因为它没有架构记忆,也没有创造一个的动机。
Archon 怎么处理
Archon 的认知循环包含一个原版 AI 完全跳过的 Model 阶段。行动前,代理对受影响子系统建心智模型:
- Pre-scan —— 读 manifest 的架构区段。理解既有边界:「API 路由调 service 函数;service 调数据访问;横切关注点(auth、cache、logging)住在中间件。」
- 架构契合检查 —— 「缓存是横切关注点。manifest 说横切关注点是中间件。所以缓存属于共享中间件,不是每个路由内联。」
- 先例查询 —— 之前是否做过类似架构决策?查
.archon/decisions.md中的项目 ADR。如果 auth 抽到了中间件,缓存就遵循同一模式。 - 创建约束 —— 第一次正确实现后,约束锁定它:
❌ 路由处理器内联缓存 —— 使用共享 cache 中间件
代理不只是解决眼前的问题 —— 它在架构里正确的位置解决它。后来 Redis 替换 node-cache 时,要改的文件正好是一个。
诚实备注:这能力高度依赖 manifest 架构区段的准确与最新。当 manifest 落后于现实时(在快速迭代阶段发生过两次),代理的架构推理会退化。这就是漂移检测存在的原因 —— 它在差距变得危险之前强制 manifest-现实对齐。
旅程 12:「能跑就发」—— 优化永不发生
你的仪表板加载 1.2 秒。还行。你加更多特性。2.1 秒。还能接受。再加。3.8 秒。你没注意 —— 你在 localhost、硬件够快。
AI 从不说「这变慢了」。它从不 profile。它从不建议:「我们引了 15 个图表库但只渲染首屏的 3 个 —— 来 code-split 一下。」它从不注意到同一个 API 调用因为 4 个组件各自独立取数据而被发了 4 次。
性能随特性数量线性退化,AI 对此零意识。 优化只在人类注意到问题并显式要求时发生。那时修复已经是大型重构而不是小型预防性调整。
Archon 怎么处理
Reviewer 子代理在审计清单中包含性能感知启发式:
- 引用审计 —— 「这页引了 340KB 的 JavaScript 但首屏只用 80KB。建议下半屏区段动态引入。」
- 冗余取数检测 —— 「组件 A、B、C 各自独立调
GET /api/dashboard/stats。抽到共享父级 query 或用既有缓存层。」 - Bundle 大小跟踪 —— manifest 记录目标 bundle 大小。当一次交付把路由 chunk 推过阈值时,reviewer 在合并前标记。
- 主动优化提案 —— 在结构性评审(
/archon-review)期间,reviewer 不等你开口。它浮现:「过去 5 次交付页面加载时间增加 40%。这里是三个最大贡献者与提议的修复。」
既有的架构约束也在生成期防住最常见的性能陷阱 —— 视口感知加载、骨架态、渐进 hydration 是默认而不是事后想到。
关键差别:优化不是由人类抱怨触发的特殊事件。它是连续审计,内建在每次交付循环中。
聚类 4:知识演进与共享语言

重复犯错、被忽视的标准、不清晰的产品术语 —— 它们都需要同样的处理:捕获信号,放进最适配的最强载体,让未来的会话默认继承它。
旅程 13:同一错误,全新惊喜
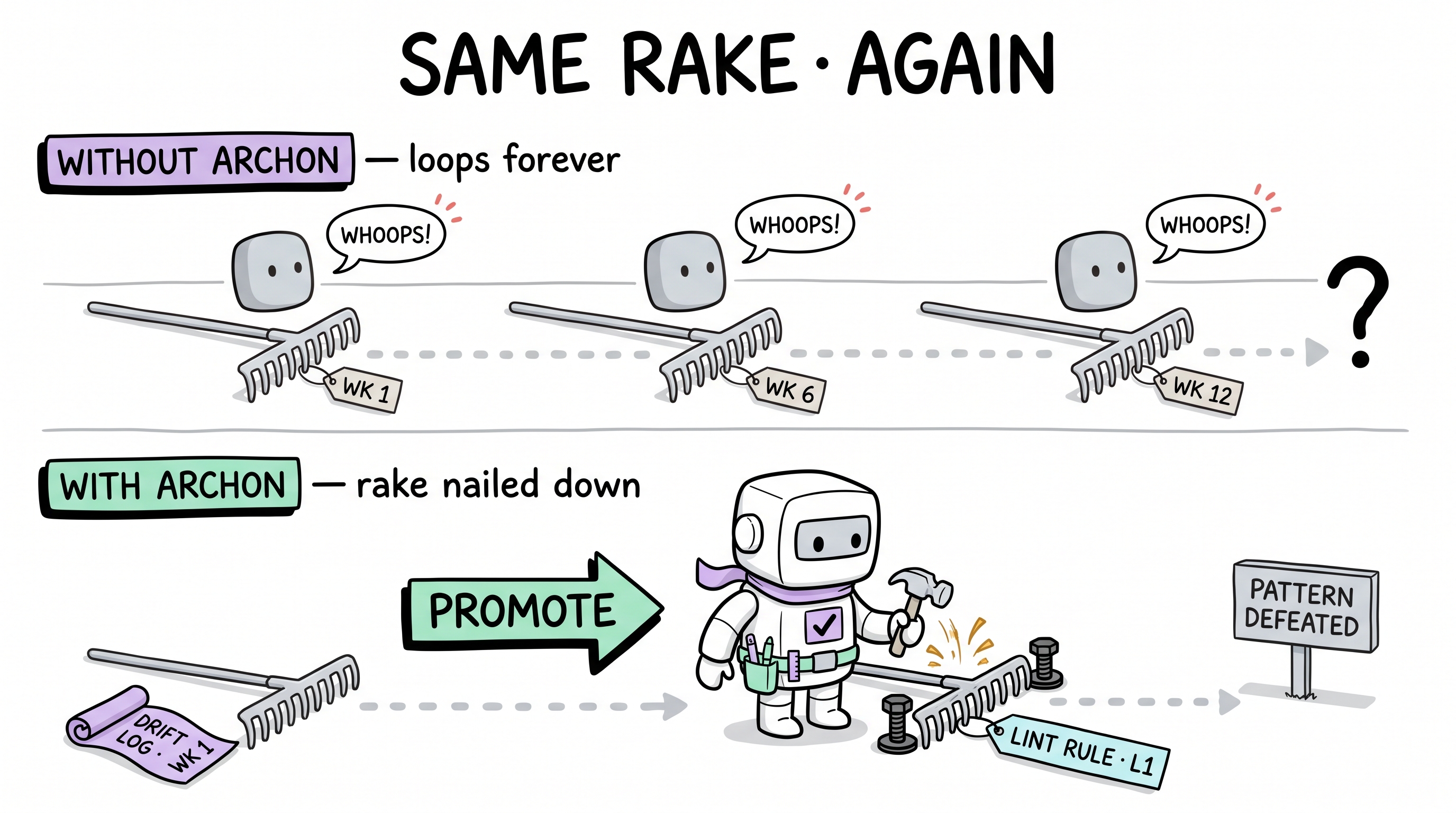
周一:AI 生成一次数据库查找。它在按 ID 查询时忘了用单条记录的 helper。查询返回数组。你抓到 bug、修了、继续。
周三:不同特性,同样模式 —— 按 ID 取一条记录。AI 写出一模一样的代码。又忘了 .single()。同样的 bug、同样的修法,相隔两天。 你又改一次。
周五:第三个特性。第三次。你这周第三次修同一个 bug。这不是复杂 bug —— 是一个单词的遗漏。但 AI 完全没机制记住自己以前犯过这个错。
把这一类乘上每一种错误:缺空检查、错的引入路径、忘了 await 异步调用、用了已弃用的 API 方法。每个 bug 对 AI 都是「新」的。你的项目积累了一份独特的错误库,而 AI 每次会话都从头重新发现每一个。
Archon 怎么处理
知识演进系统正是为此设计。当代理撞墙时 —— 或当一个模式重复时 —— 系统触发结晶循环:
- 触发识别 —— 代理(或 capture-auditor)检测到重复模式:「这是第二次按 ID 查找返回了集合而不是一条。」
- 教训捕获 —— 错误被抽成一条具体规则:
❌ 按 ID 查找而无单条断言 —— 按 ID 查找必须返回恰好一个实体或带类型的 not-found 结果 - 约束安置 —— 规则进入约束金字塔的可强制最强层。本例中加进项目的数据访问 skill 文档 —— 一个会被加载进每个相关会话上下文的文件。
- 自动强制 —— 下次会话,AI 在生成时就看到约束。它不需要「记得」那个 bug —— 约束在它写出之前就阻止了。
结果是一个项目特定免疫系统。项目遇到的每个错误一次后变成永久抗体。第 50 个特性是带着前 49 个的累积教训写出来的 —— 不是 AI 变聪明了,而是约束库长大了。
诚实备注:结晶不是字面意义上的自动 —— capture-auditor 提议约束,它们在进系统前被验证。早期版本试过完全自动结晶,但产生太多假阳性(一次性错误本不该变成永久规则)。当前设计要求模式至少出现两次,或在结构性评审中被标记。
旅程 14:规则写了,规则被忽视
你的团队写了 CONTRIBUTING.md:「所有 API 路由必须用 Zod 校验请求体。所有数据库查询必须经过 service 层。所有组件必须用设计系统的 Button,而不是原生 <button>。」
你告诉 AI:「按我们的 CONTRIBUTING.md 来。」
第一个任务:AI 读了它,完美遵守。第二个任务:又读一次,大体遵守。第三个任务:上下文窗口被代码挤满 —— AI 悄悄把 CONTRIBUTING.md 从注意力里丢掉。 它写了原生 <button>。它把数据库查询直接放进 API 路由处理器。它完全跳过了 Zod 校验。
基于文档的标准不奏效,因为 AI 把文档当建议,不当约束。 一次性读个文档不会形成肌肉记忆。没有强制 —— 只有「希望 AI 每次任务、每次会话都重读并遵守」。
Archon 怎么处理
这正是 Archon 约束金字塔背后的根本洞察:把每条规则推到尽可能强的强制层,不是最方便的层。
金字塔有 6 层,从强到弱:
| 层 | 机制 | 强制 | 例 |
|---|---|---|---|
| L0 | 类型系统 | 编译期错误 | TypeScript strict 模式抓缺字段 |
| L1 | Linter | 提交前阻断 | ESLint 规则禁设计系统外的 <button> |
| L2 | 编辑器规则 | AI 上下文注入 | .cursor/rules/ 加载进每次生成 |
| L3 | Skill 文档 | 会话级指引 | 数据访问模式、状态管理模式按任务加载 |
| L4 | ADR | 决策记录 | 「我们选了 Zod 而不是 Joi 因为...」 |
| L5 | Manifest | 项目级上下文 | 架构边界、技术栈、约定 |
关键:「所有组件必须用设计系统的 Button」不会停在 CONTRIBUTING.md 里的一行(L5,最弱)。它被晋升:
- 首先,它变成编辑器规则(L2)—— 每次组件文件编辑时注入 AI 上下文窗口
- 然后,如果违规仍存在,它变成 lint 规则(L1)—— 代码字面上无法带原始
<button>通过 CI - 如果类型系统能强制(如自定义 JSX pragma),它移到 L0 —— 编译错误
标准不是用来读的文档。它们是让违规变得不可能的结构性约束 —— 或至少立即可见。
诚实备注:不是每条规则都能到 L0 或 L1。「数据库查询用 service 层」很难 lint。但约束金字塔强制问那个问题:「这条规则能到的最强层是什么?」大多数团队从不问。他们写一页 wiki 然后纳闷为什么没人遵守。
旅程 15:「你说的那个产品词是什么意思?」
在传统软件团队里,新项目最先发生的事之一是术语对齐。产品、设计、工程坐下来一致:「我们说这个产品词时指的是这个具体的东西。我们说那个工作流名时指的是那个。」这是基础 —— 基础到大多数团队甚至不把它当一个流程。这只是有能力的人合作时做的事。
AI 没有这种机制。零。
问题分三层
第 1 层:用户说话,AI 听不懂。
你在做卡牌游戏。你的团队发明了一个概念叫「覆面卡」(face-down card)—— 它是一个特定游戏机制,关于何时可翻、什么触发揭示、它如何与计分系统互动有规则。
你开新 AI 会话:「给覆面卡加一个翻牌动画。」
AI 不知道「覆面卡」什么意思。它开始猜。是 back-card?side-card?hidden-card?它在代码库全文搜索,找到三个听起来类似的概念,从碎片里拼出一个 Frankenstein 理解。它选错了。你花 20 分钟纠正它,从头解释概念。下一次会话,又来一遍。
第 2 层:AI 说话,用户听不懂。
更糟:也许 AI 三次会话前真的构建了覆面卡系统。它创建了 FaceDownCard 组件、CardReveal 状态机、flipTrigger 事件系统。它精确地知道这个概念是什么 —— 在代码里。
但用户不知道「覆面卡」这个词。他们说:「我想改那些卡牌的行为,你知道,那些被反扣放着、然后某个事件发生时翻开的卡。」
AI 现在得逆向工程这段 15 字描述映射到它已经构建的 FaceDownCard 组件。也许成、也许不成。它绝对说不出:「你是说覆面卡?这是它在我们系统里的样子。」它没有共享词表可以拿出来。
第 3 层:没人对齐,所有人漂移。
几个月下来,产品积累了几十个原创概念。一些是用户造的、一些是 AI 造的、一些从代码里有机出现。没有共享术语表:
- 用户说「booking」指生命周期实体。AI 解读为「日历预约」。
- AI 创建了「draft-to-publish」流程。用户称它「launch prep」,从未连接两者。
- 代码里出现一个新概念
CapabilityPackage。用户称它「skill config」。两边都没意识到他们在说同一件事。
代码库说一种语言。用户说另一种。AI 猜第三种。 每次交互都把 token 烧在翻译上,误译随时间复利。
这正是术语对齐会议在人类团队里防止的事。但 AI 没有等价物 —— 没有 onboarding、没有词表交接、没有「我们这里这样叫东西」。
Archon 怎么处理
Manifest 包含一个 Concept Glossary —— 一份紧凑术语表,包含在当前状态热路径中:
| 术语 | 在本项目的含义 | ≠ 通用含义 |
|---|---|---|
| Booking | 客户委托的生命周期对象(pending→active→paused→completed→cancelled) | ≠ 日历预约 |
| Launch Prep | 把草稿材料转化为可发布资产的工作流 | ≠ 营销发布计划 |
| Capability Package | 代理可执行的结构化 skill 包(prompt + config + metadata) | ≠ 工作经历或用户体验 |
对于间接描述或同一工件的多个名字,Manifest 还携带一份 User Language Index:干系人措辞 → 规范目标 → 路由/路径/文件查找。
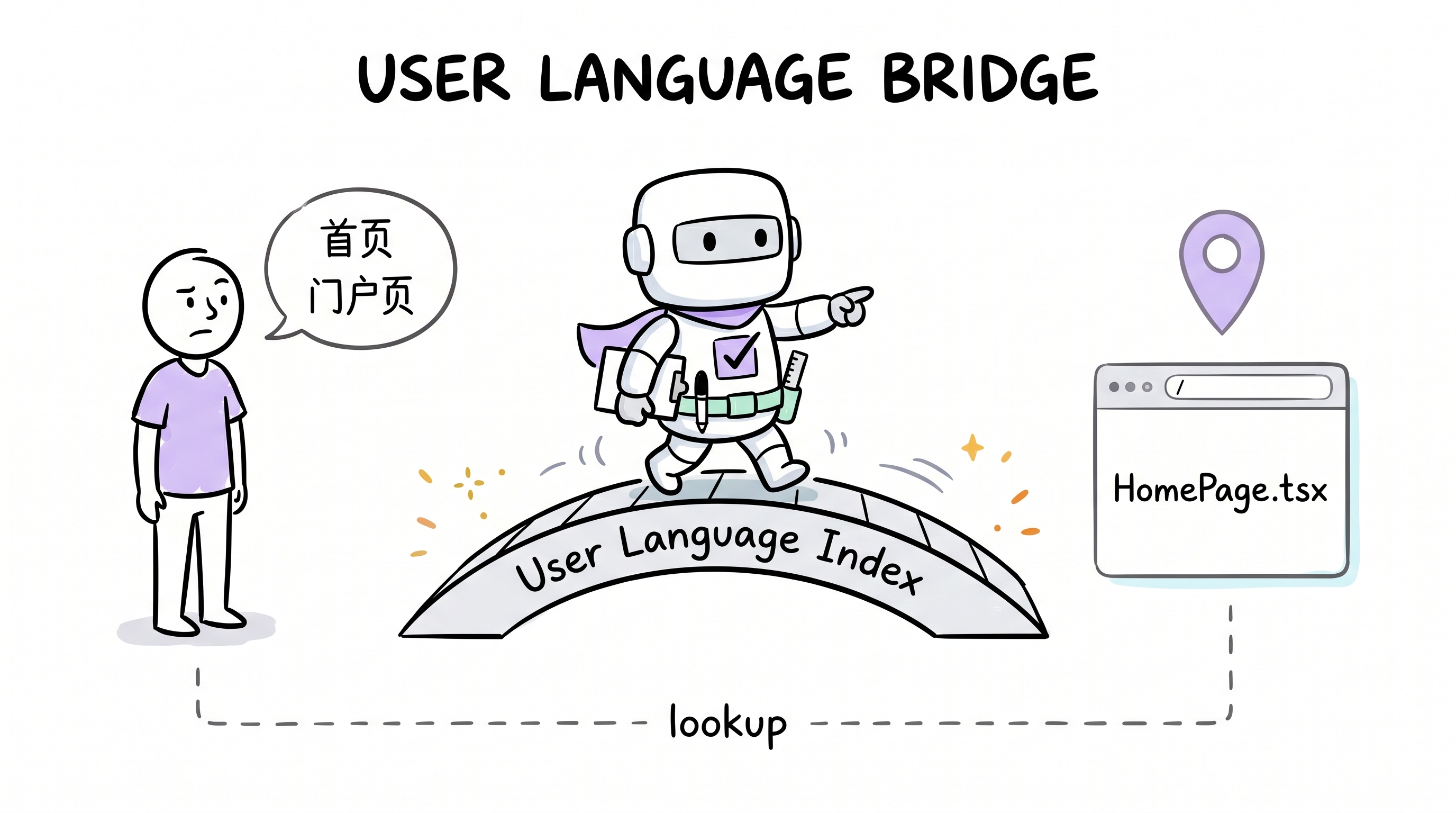
索引不只是被动表 —— /archon-demand §Pre-Scan 在每次非 fast-path 需求上跑一次 User language alias scan,三种确定性结果:
- 命中 —— 措辞匹配某 ULI 行 → 静默解析到规范目标,并且如果用户可能不知道规范名,用一句
"我们项目里把它叫 X。"补桥 - 近似命中 —— 需求用了一个常出现、可能指向已有工件但还不在索引里的措辞 → 用尽力而为的映射继续,记录
uli_candidate: <phrase> → <target>供 Close-Out 晋升 - 未命中 —— 没有干系人特定措辞 → 记录
uli_scan: n/a
Close-Out 然后要么把记录的候选晋升进索引(由交付改动确认),要么以理由丢弃。这把索引从「加载了但可能没用」变成每次需求都会被查阅的咨询点。
这解决三层:
第 1 层解决 —— 用户→AI:词表是当前状态热路径上下文。当用户说「覆面卡」,AI 已经有定义 —— 不猜、不考古。它立即知道这映射到带特定翻牌触发规则的 FaceDownCard。
第 2 层解决 —— AI→用户:当用户描述「那些反扣放置的卡」时,AI 可以主动补桥:「那是我们的覆面卡(FaceDownCard 组件)。这是它的工作方式。」词表实现主动词汇对齐 —— AI 不只是被动理解术语,还能反过来教给用户。
第 3 层解决 —— 持续对齐:知识演进系统把概念发现当成触发事件:
- 发现触发 —— 当代理遇到一个可能被误解的术语(来自用户输入或既有代码)时,标记它进行捕获。
- 词表捕获 —— Close-Out 期间向 manifest 词表添加新术语,附简洁定义和「不是这个」列以与通用含义区分。
- 双向对齐 —— 当代理检测到用户描述的东西已在词表或语言索引中有别名(或反过来)时,它主动对齐:「我们项目里把它叫 X。」这是「我们用同样术语吧」的数字等价。
词表故意精简 —— 一行定义,不是文档页。它回答「这个词在这里什么意思?」而不是「这个系统怎么工作?」(那是架构文档的活)。保持精简意味着它能留在当前状态热路径而不消耗预算。
诚实备注:这是有能力的工程团队本能做的事 —— 维护共享词表。AI 辅助开发需要为此显式机制这一事实,揭示了我们对人类团队对齐有多么习以为常。词表不是聪明工程。它是最基础的协作卫生,终于交给了 AI。
旅程 16:那条悄悄消失的规则
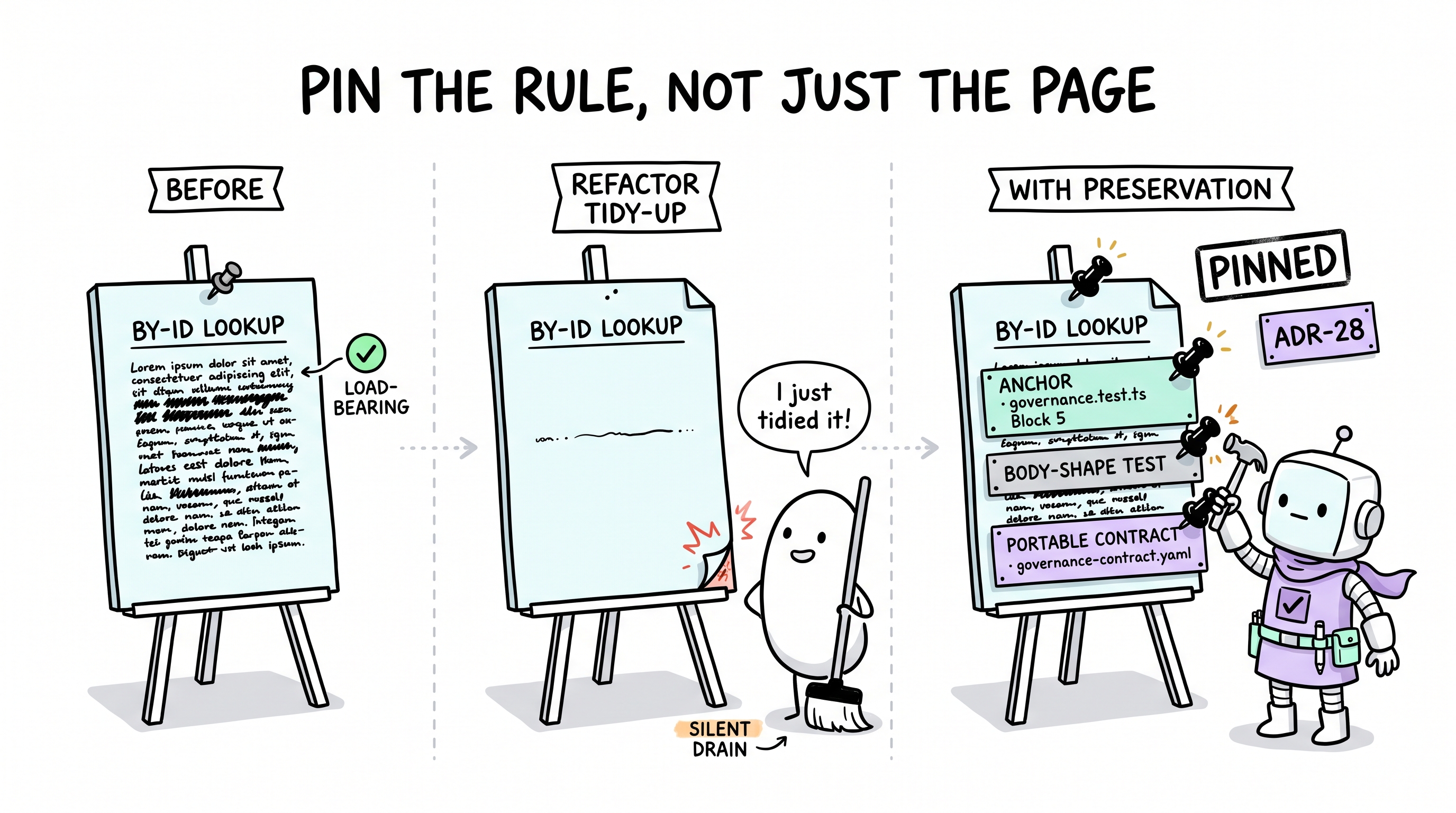
六个月前,你的团队遇到一个 bug。修法不复杂 —— 是数据访问层加的一行守卫:「按 ID 查找必须用 .single() 或返回带类型的 not-found。」从那以后,那条守卫一直在悄悄防 bug,对你也对 AI。你从未见过那些没发生的 bug,因为守卫在那里。
上周,有人重构了数据访问文件。他们出于善意 —— 在整理。整理过程中,.single() 守卫段落被无意缩成了「小心处理按 ID 查询」。同样的锚标题、同样的文件名、不同的实质。规则没被删。它被无声抽空了。
测试套件仍然过 —— 从来没有一个测试是「这段段落存在」。文件预算仍然容得下 —— 实际上文件还更小了。没有 linter 抱怨。没有 reviewer 标记,因为对一个从上往下读的 reviewer,「小心处理按 ID 查询」听起来合理。
两个月后,bug 回来。不戏剧化 —— 慢慢的,每个特性一个,跨三个会话。等有人把它们连起来时,守卫已经缺席数周。你不是在防新问题。你在防一个你已经解决过、却悄悄自我未解的问题。
这是大多数演进系统看不见的失败模式:它们只衡量什么变了。它们不衡量什么必须仍然奏效 —— 所以一条承重规则的无声抽空看起来跟没改一样。
Archon 怎么处理
ADR-28 Preservation Axis 给演进加上第二种运动:结晶捕获什么应改;保留捕获什么必须留。每次交付的 Close-Out 交付后评审同时问两个问题:
- (a)(b)(c) 下次该改什么?→ 结晶
- (d) 这次交付依赖了什么、不能悄悄抽空的?→ 保留
当交付依赖了一条承重规则时,保留产出机械三件套 —— 不是散文提醒:
- Critical-rule registry 锚点 ——
governance.test.tsBlock 5 的子串断言。把段落缩短或重写的未来重构在 PR 合并之前失败测试。 - Body-shape 测试 —— 当锚点是标题时,单独的 describe block 断言下面的 body 保留其鉴别性实质(表列、token 边界、分类行)。
- 可移植契约条目 —— 同一规则钉在
governance-contract.yaml,让非 TS 采用方通过archon-check.py强制。
钉是绊线,不是墙。你仍可以移除被钉规则 —— 但移除必须是显式、可审计的跨三文件编辑(锚点 + 测试 + 契约),不是无意散文缩短。这正是演进(我选择移除它,理由有记录)与向最近修复漂移(规则在没人看时褪色)的差别。
退化守卫:claim-verifier preservation 模式(ADR-27)拒绝两种会掏空运动的形:(i) none-this-cycle(...) 带模糊证据(<40 字符或缺扫描动词 —— 「checked」而不命名扫了什么),以及 (ii) 首过交付把自己刚加的锚点钉为仿佛挺过了一个周期。两者必须要么产出真证据,要么等到下个周期。
结果:Archon 不只是记错(旅程 13)—— 它也保护它的成功。一条六个月前防住 bug 的规则被结构性地阻止悄悄消失,即便其所在文件被一个不知道规则承重的人重构。
诚实备注:保留是最容易跳过的运动,因为「我留住了既有规则」是默认假设的回答。Close-Out 清单强制把答案写成两种显式形之一 ——
pinned(anchor+test+contract)或none-this-cycle(<带动词与目标的命名扫描>)—— 校验器对挥手字符串 fail closed。没有那个机械形,保留就坍缩回散文提醒,那正是它要防的失败模式。
模式
每段旅程都有同一个根因:
AI 为当前请求做局部最优,而不是为代码库的长期健康做全局最优。
这不是缺陷 —— 它是无状态、无记忆系统的本性。解决方案不是让 AI「想得更深」。解决方案是给它一个正确选择就是默认选择的环境。
那就是 Archon Protocol:一个把 AI 局部最优决策转化为全局一致工程产出的操作系统。
| 没有 Archon | 6 个月后 | 有 Archon |
|---|---|---|
| 文件膨胀直到有人发现 | 单文件 2000 行;重构成本超过重写 | 主动检测膨胀并拆分 |
| 模式跨会话漂移 | 5 种范式共存;新开发者 onboarding 3 天 | 约束锁定已验证模式 |
| 昨天的决策被遗忘 | 同样的辩论每周重打 | Manifest 持久承载决策 |
| 复制粘贴直到 bug 扩散 | 一份的 bug 修了,3 份还坏着 | 三次法则触发抽象 |
| 错误处理逐页彩票 | 用户碰上 4 种不同错误 UX | 知识演进强制一致 |
| 测试可选直到不可选 | 16 端点零测试零信心重构 | 交付卫生标记 + 里程碑门阻断 |
| 新技术采纳无说明书 | 每会话从头重学框架 | 采纳 skill 与技术同时交付 |
| 代码上线、文档没上 | 产品能跑但没人能解释怎么工作 | Manifest + 漂移检测让文档同步 |
| AI 思考前先写 | 半成品交付要「撤销并按计划重来」 | Verdict 门强制在第一行代码前分解 |
| 没有架构推理 | 同一横切关注点 7 个内联实现 | 认知循环行动前对子系统边界建模 |
| 优化只在人类抱怨时 | 线上才发现 4 秒页面加载 | Reviewer 跨交付连续审计性能 |
| 同一错误每会话重复 | 一周内 3 次修同一个单词 bug | 知识演进结晶教训为永久约束 |
| 开发标准写了不被遵守 | CONTRIBUTING.md 第一任务后被忽略 | 约束金字塔把规则晋升到可强制最强层 |
| 产品术语每会话丢失 | AI 猜「覆面卡」=back-card?side-card?烧 token 重建含义 | Manifest 词表启动共享词汇;AI 主动双向对齐术语 |
| 承重规则被重构无声抽空 | 六个月旧守卫从「整理」commit 中消失;它防的 bug 慢慢回来 | Preservation Axis 把每条承重规则钉为锚点 + body-shape 测试 + 可移植契约(ADR-28) |