强模型不需要框架 —— 真的吗?
AI 工程社区里反复出现的一场辩论:模型 vs 鞍架。一派认为模型能力在指数级增长,任何框架都是冗余约束 —— 是拖慢千里马的鞍。另一派认为没有框架,再强的模型也只能做局部最优决策。这篇笔记不站队。它只是问几个问题。
读者:怀疑论者、正在评估是否采用 Archon 的决策者,以及任何想过"我的模型够强了,不需要流程"的人。如果你想看架构层面的回答而不是哲学回答,读 architecture.md。
核心主张很简单:模型提供推力,工程环境提供方向。Archon 不是为了"约束模型"。它是为了给一个强模型正确的输入、边界与反馈。
把论点摆到桌面上
"模型在变强。GPT-5 一次能读 10 万行。Claude 能拆任务、自主执行。再过一年,你的 system prompt、规则文件、生命周期 hook 全都会冗余 —— 模型自己就知道该做什么。"
这个论点的前提是:模型的瓶颈是推理与编码。如果推理够强、代码质量够高,工程问题就消失了。
我们不质疑这个前提。模型确实在变强。但我们质疑一个隐含假设:
工程问题真的根源在"不够聪明"上吗?
六个问题

下面六个问题没有一个跟"模型不够聪明"有关。缺的依次是:词汇、决策日志、停止触发、独立评审、历史模式库、清晰的工程角色。
1. 即便最强的模型 —— 它知道你项目的行话吗?
你的产品有一个概念叫 "FaceDownCard" —— 一个特定的游戏机制,带翻牌触发规则、计分交互、状态机。这个词是你团队发明的。
你打开一个干净会话,告诉世界上最强的模型:"给 FaceDownCard 加一个翻牌动画。"
它会怎么做?
它不知道 FaceDownCard 是什么意思。它 grep 代码库、找到三个相似概念(back-card、side-card、hidden-card)、缝出一个科学怪人式的理解 —— 然后挑错了。
这不是推理问题。是信息问题。 模型不缺算翻牌动画的算力;它缺的是那条语义锚点:"这十几个字符在这个项目里指那个具体的工件。"
更糟:三个会话之前,正是这个模型本身创建了 FaceDownCard 系统(组件 FaceDownCard、状态机 CardReveal、事件 flipTrigger)。但用户不记得这个词,描述成"那个一开始背面朝上后来翻过来的卡"。模型现在得反向工程:这 11 个词 → FaceDownCard。它甚至无法主动反问"你是说 FaceDownCard 吗?"。
因为它没有共享词汇。
推理不解决这个。100 万 token 的上下文窗口也不解决 —— 词汇问题不是上下文长度问题,是没人告诉过模型这个词在这个项目里意味着什么。
2. 即便最强的模型 —— 它记得上周被否的那条提议吗?
上周你们辩论过是否要迁移到一个新的应用框架。结论:爆炸半径太大,当前里程碑不需要全栈替换,只有一小撮页面受影响。否决。 替代方案是更小、有界的优化。
新会话。你提到首屏慢。模型的第一反应?
"我建议迁移到一个新的渲染框架。"
它不知道这条提议上周已经被否了。 不知道为什么否。不知道你已经有替代路径。它从头重推、得出和上周一模一样的结论 —— 再被否一次,浪费 20 分钟重新解释。
这不是 IQ 问题。一个 IQ 200 的新员工第一天上班也不知道上周架构评审否决了什么。他们不需要更高的 IQ。他们需要会议纪要。
3. 即便最强的模型 —— 它知道何时该停下来吗?
你和模型连珠炮般出了十个特性。代码又快又干净。每次提交都能编译、测试都过。
你不知道的是:第三次交付引入了一种新的状态管理模式。第五次交付引入了另一种。第七次交付悄悄推翻了第三次的命名约定。到第十次时,三种状态管理范式在代码库里并存,没有任何一种被宣布为标准。
每次交付都是局部最优的。 模型每次提交都做了对的事。但全局是一团糟。
为什么?因为模型没有"停下来看看大局"的机制。它没有同事、没有日历、没有"等等,哪儿不对劲"的本能。人类工程师有 code review、站会、retro。模型没有。
再强的推理也不会让模型自发说出"等一下,先做次完整复审。" 它需要一个外部化的、量化的、不可跳过的触发器,才能打破"接需求 → 写代码 → 接需求 → 写代码"的死循环。
4. 即便最强的模型 —— 它能审计自己刚写完的代码吗?
你花一天写一篇文章,然后自己校对。能抓出多少错?几乎抓不到。不是因为你语言能力差,而是因为沉没成本偏差 —— 你的脑子会自动为刚刚重金投入的产物找合理化解释。
LLM 一样。在同一个上下文窗口内,刚生成代码的模型,在评审它时天然偏向"看起来挺好"。不是因为代码真的好,而是因为生产者和评审者是同一个实体。
这不是能力问题。是角色冲突。 即使在 AGI 级推理水准下,作者和裁判共享上下文 = 利益冲突。人类公司从不让作者做最终评审。这是工程管理 101。
5. 即便最强的模型 —— 它注意到上周修过同一个 bug 吗?
上周一:一个组件因缺少 null 检查崩溃。模型修了。周三:另一个同类组件,同样原因崩溃。模型修了。这周:第三个组件 —— 同一个问题。
三次独立的正确修复。零次根因分析。
因为对模型来说,每次修复都是"一个新问题"。它没有机制注意到"这是同类问题第三次出现"了。它不会想"问题也许不在某个具体组件,而在制造它们的模板或约定上"。
够强的模型可以无瑕地修每一个具体 bug。但修 bug 和消除根因是完全不同的两件事。前者需要推理;后者需要模式识别 —— 而模式识别要有历史可看。
6. 即便最强的模型 —— 它知道何时该顶回去吗?
你说:"用 Redis 做缓存。" 你是产品负责人,不是架构师。你这么说是因为你刚在 Hacker News 上看了一篇赞美 Redis 的帖子。
一个"够强"的模型会怎么做?
- 如果它的角色是 assistant —— 它执行。你是老板。三个月后你发现你那个三用户的 MVP 上跑着一个 Redis 集群,运维成本超过应用本身的总和。
- 如果它的角色是 engineering owner —— 它说:"以你的规模,内存缓存就够了。Redis 引入了不必要的基础设施复杂度。我不建议这么做。"
能力不决定行为 —— 定位决定行为。 一个"够强"的模型可以执行你的烂主意,也可以拒绝它。问题是:什么决定了它选哪一个?
你其实在争两件不一样的事
"模型 vs 鞍架"的辩论永远没结论,是因为参与者把两类完全不同的问题混为一谈:
| 类别 | 问题性质 | 模型能力能解决吗? |
|---|---|---|
| 推理问题 | 代码不够好、设计不最优 | ✅ 模型更强 = 代码更好 |
| 环境问题 | 上下文缺失、记忆缺失、没有自我监督 | ❌ 没有任何模型能猜出你没告诉它的事 |
上面六个问题,没有一个是推理问题。六个全是环境问题:
- 行话 —— 信息缺口,不是推理缺口
- 否决记忆 —— 上下文不连续,不是思考太浅
- 全局复审 —— 没有触发机制,不是不愿意停
- 自审 —— 角色冲突,不是能力不够
- 模式识别 —— 没有历史,不是看不出模式
- 独立判断 —— 定位含糊,不是没有意见
推理能力解决"怎么做"。环境解决"在什么上下文里做"。
把一个 IQ 200 的天才扔进一个不熟的公司 —— 没有项目文档、没有会议纪要、没有 code review 搭档、没有产品词汇表 —— 他能干好工作吗?
能。他写的代码顶级。但他会重新发明轮子、误读需求、悄悄推翻前人的决策、用通用词替掉内部行话。不是因为他不够聪明 —— 是因为没人给他一个能正常运转的环境。
鞍架还是发射台?
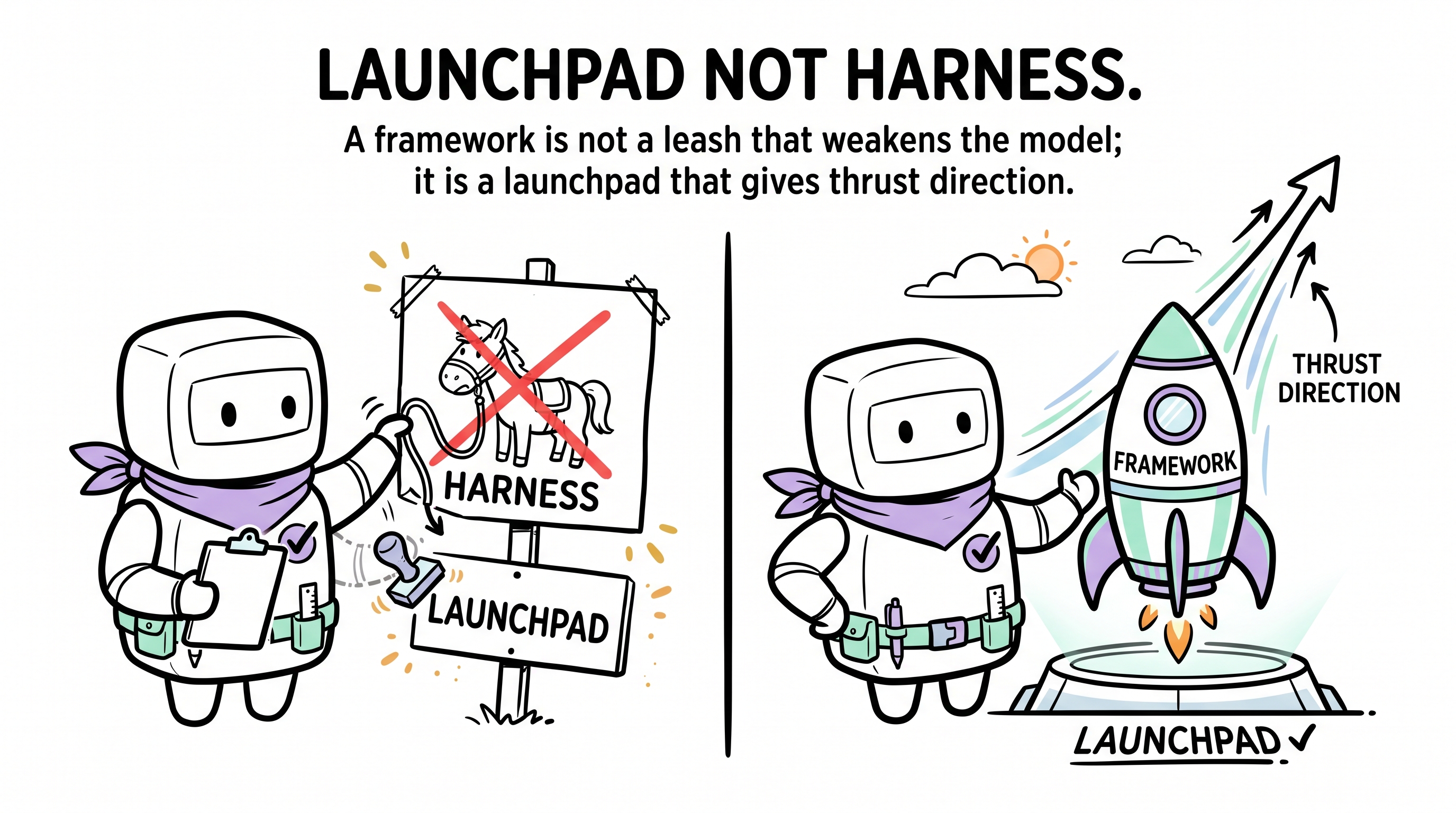
"鞍架"这个词自带贬义。绑、限、缚。
但想想:
鞍架的意义不是让马跑慢点 —— 是让马朝对的方向跑。
没有鞍架的千里马可以跑一千里 —— 朝错的方向。一天跑一千里且方向对的马,才有价值。
话虽如此,我们觉得"鞍架"这个词本身有误导。它暗示模型是头需要驯服的野物。一个更准的比喻:发射台。
火箭的推力来自它自己。没人怀疑发动机。但发射前,火箭需要:
- 一套坐标系 —— 目标在哪?(项目上下文、产品定义、概念词汇表)
- 轨道参数 —— 哪些约束适用?(技术栈、架构决策、质量门)
- 遥测系统 —— 偏航了吗?(漂移计数器、周期性评审、知识演进)
- 分离机构 —— 何时抛掉助推器?(执行/裁判分离、子代理委派)
发射台不削减推力。它指引推力。移走发射台,火箭照样点火 —— 只是它会原地打转。
我们的选择
Archon 不是一组规则,不是一堆 system prompt,不是 prompt 工程小技巧的合集。
它是一个工程环境,处理那些光靠能力解决不了的问题:
| 模型不知道的事 | Archon 怎么解决 |
|---|---|
| 这个项目里某个业务词是生命周期实体,不是日常含义 | Manifest 概念词汇表,每次 boot 都加载 |
| 你上周否决过一次大迁移 | 干系人备忘,每次 demand 接入前扫描 |
| 十次交付之后,认知模型已经严重发散 | 漂移计数器 + 阈值强制评审 |
| 自评自己的代码 = 利益冲突 | 执行者/评审者分离,委派给独立子代理 |
| 同一类 bug 修了三次都没做根因分析 | 知识演进:触发 → 捕获 → 结晶 |
| 用户在表达产品意图还是技术指令? | 所有权模型:模型是工程所有者,不是助手 |
这些机制没有一条是约束推理的 —— 它们给推理喂正确的输入。
一个已经知道"这个业务词在本项目里是生命周期实体"的模型,比一个要花 2000 token 从代码库里考古重建那个事实的模型,推理效率高得多。
一个已经知道"那次大迁移上周被否了"的模型,不会浪费五分钟重推一个已解决的问题。
一个被强制每十二次交付就停下来做完整复审的模型,不会在不知不觉中让三种设计范式并存。
环境不是约束。环境是让推理别浪费在那些本不该需要去推理的事情上。
一个思想实验
假设模型能力达到完美 —— 推理永远正确、代码永远无 bug、架构永远最优。
- 它还需要知道你们的行话吗?需要。
- 它还需要知道上周的技术决策吗?需要。
- 它还需要被提醒"该看看大局了"吗?需要。
- 它还需要一个独立角色来评审它的工作吗?需要。
这些需求不会随着模型变强而消失。因为它们不是对模型弱点的补偿 —— 它们是软件工程本身的内在要求。
人类工程团队有词汇表、纪要、code review、retro。不是因为工程师不聪明,而是这些是协作系统正常运转所需要的基础设施。
AI 工程只是把"人-人协作"换成了"人-AI 协作"。基础设施需求没变。变的是 —— 现在没人记得也要给 AI 把基础设施搭起来。
所以,模型 vs 鞍架?
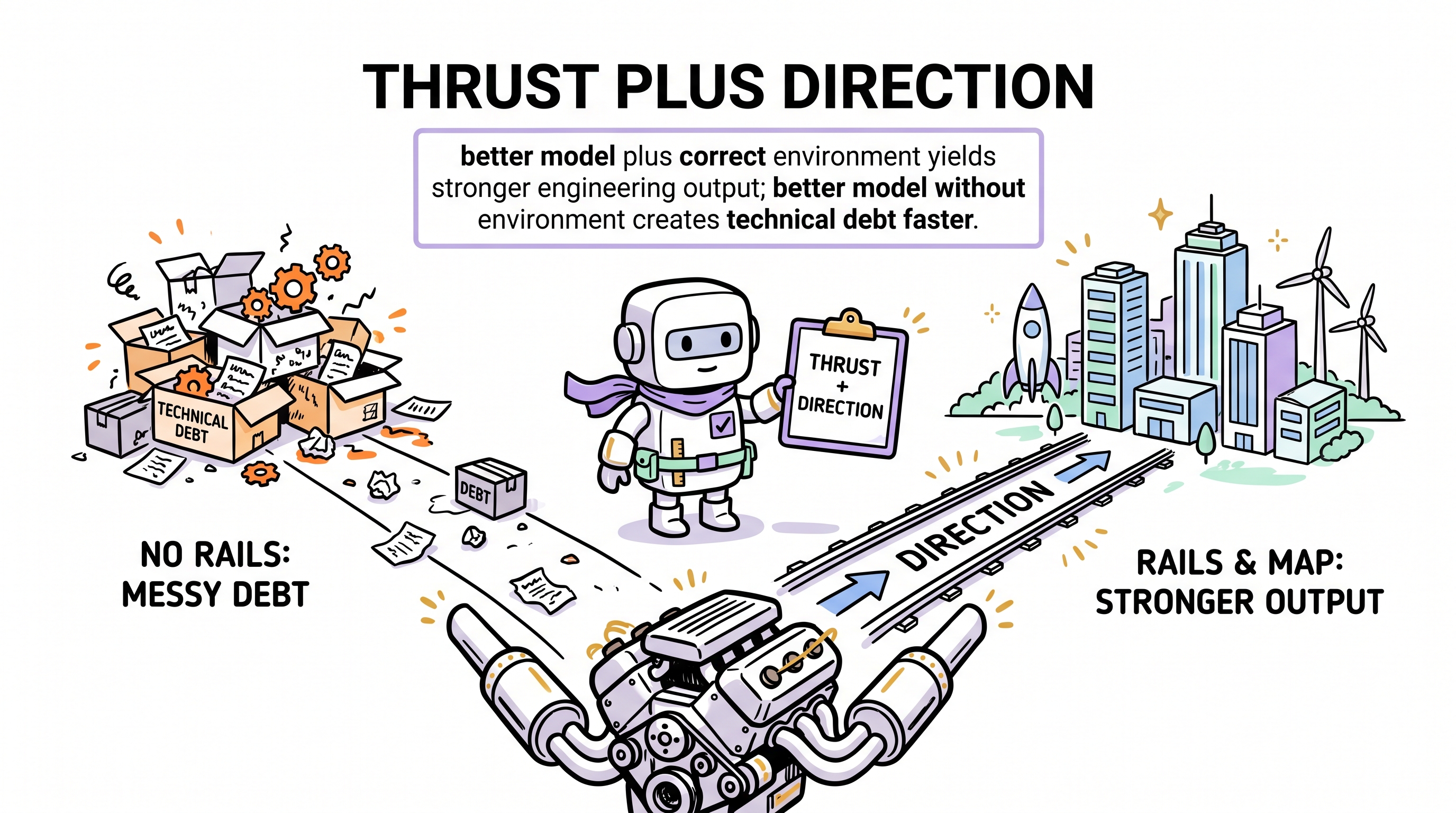
这不是对立的两极。
更强的模型 + 对的环境 = 更强的工程产出。 更强的模型 + 没有环境 = 一台更高效的技术债务工厂。
鞍架派的错误是把"框架"读成"限制模型能做什么"。真相是 —— 一个好框架扩展了模型能做什么:它把模型从"当前请求的局部最优执行者"变成"理解全局上下文的工程所有者"。
模型提供推力。环境提供方向。两者都不可省。
本文是 Archon 工程治理设计笔记的一部分。Archon 是一个跑在 AI 结对编程 IDE 里的、基于会话的工程治理框架。
延伸阅读:user-journeys.md —— 16 个真实案例,展示这些环境问题如何在实践中浮现并被解决。architecture.md —— Archon 的完整架构。