Installing a "Memory Decay Alarm" on a Stateless AI — The Design Rationale Behind Archon's Drift Mechanism
This article explains the design motivation, operating principles, and actual problem scope (and limitations) of the drift (cognitive drift) and periodic review mechanism in the Archon framework.
Audience: readers who want to understand why drift exists and how its tiered thresholds behave — not just how to operate it day-to-day. For the mechanism as it actually runs inside a delivery, read architecture.md §Knowledge Evolution System and the wake/close-out flow in
{platform}/commands/archon-demand.md.
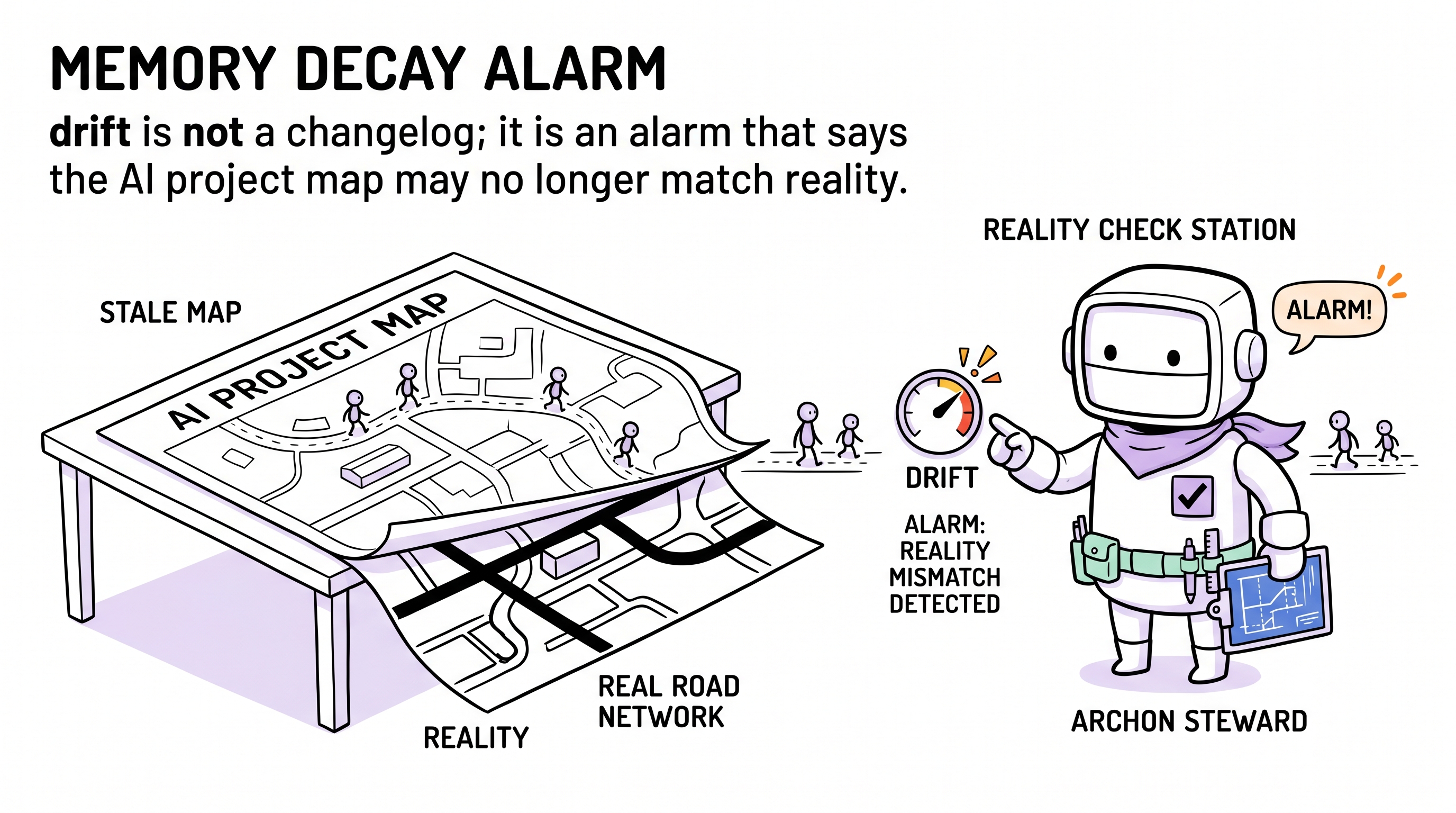
Drift is Archon's memory-decay alarm: it does not duplicate Git history; it tells the agent when its project map may no longer be trustworthy enough to keep delivering blindly.
A Problem You May Not Have Noticed
You've been pair-programming with an AI all afternoon. It added three features, refactored the data layer, and introduced a new library. The next morning, a new session reads the project files and still uses the old pre-refactor pattern, because it has no lived memory of yesterday.
This isn't a bug. It is the fundamental reality of LLM sessions: every session starts from a blank slate.
The smart approach is writing project state into files — manifest, spec docs, rule files — so the AI loads them on every boot. But this creates a more insidious problem:
Who ensures those files themselves haven't gone stale?
You delivered ten times straight, changing code each time, but the manifest was only updated six times. Rule files still describe yesterday's architecture. Skill examples may no longer compile. A widening gap has opened between the "project truth" the AI reads and the project's actual state.
That gap is drift.
Drift Is Not a "Changelog"
First, let's correct a common misconception: drift doesn't track "which files changed." Git already does that, and does it better than any markdown file.
Drift tracks: the rate at which the AI's cognitive model diverges from project reality.
Imagine you have a map. Every time you walk a new road, the map doesn't get updated. One or two roads are fine — you remember. After ten, you start getting lost. The problem isn't "ten roads aren't drawn" — the problem is "how much should you still trust this map?"
The drift counter is the inverse of that trust level. It doesn't tell you what's wrong — it tells you: it's time to stop and see the full picture again.
Quantification
After each delivery, the main agent assesses the cognitive impact of the change:
| Complexity | Meaning | Score |
|---|---|---|
| trivial | Single-file change, config tweak | +1 |
| small | 2-5 files, no new patterns | +2 |
| medium | New module, new pattern, 5-10 files | +3 |
| large | Architecture change, cross-layer modification | +5 |
Note that what's being assessed is cognitive complexity, not diff line count. A three-line API signature change that affects ten callers has far greater cognitive impact than a fifty-line new component.
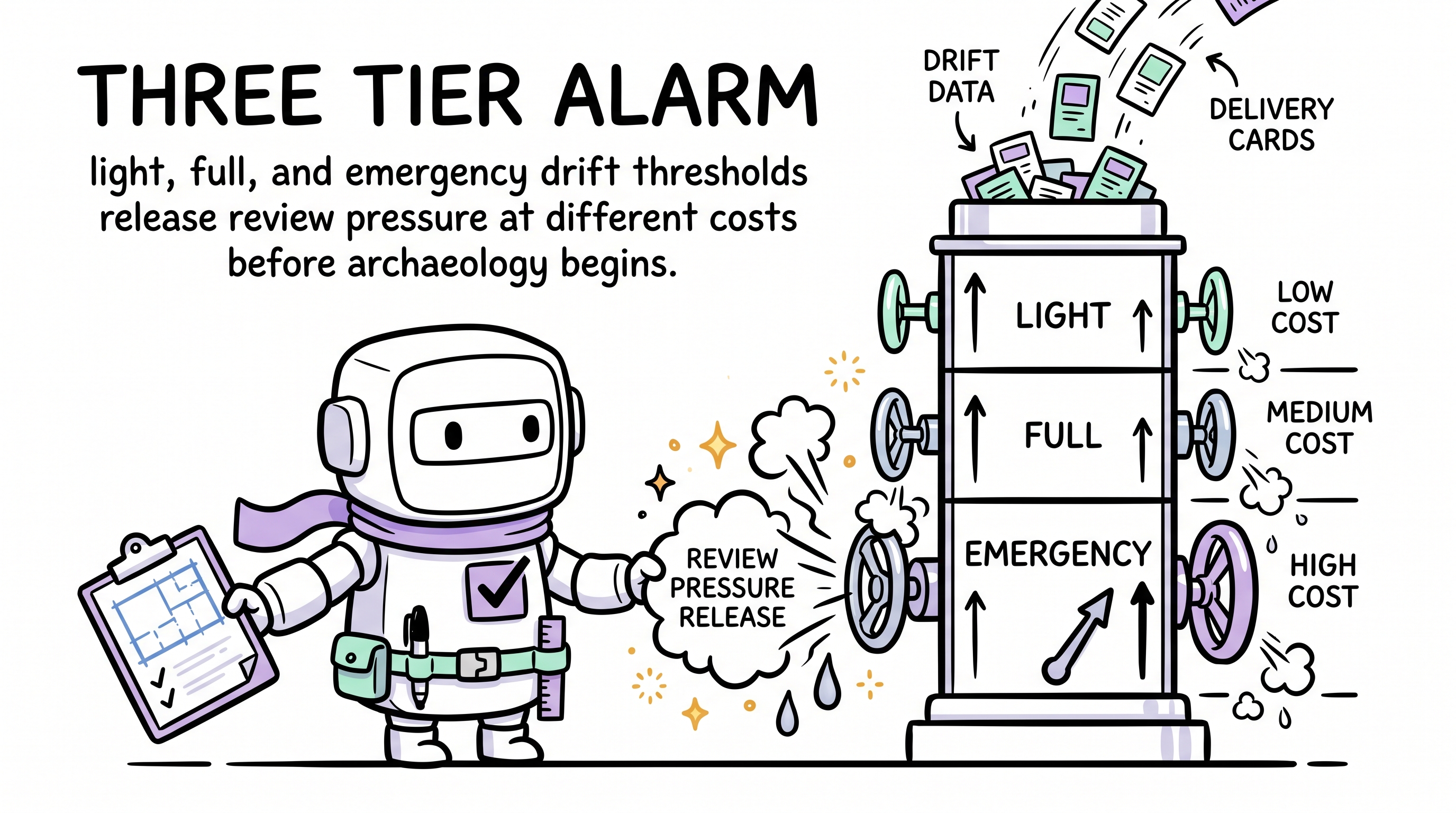
Thresholds are tiered. Three gates (light / full / emergency) release pressure at different cadences, replacing a single-gate binary trigger that was shown to fail under real load (see ADR-9).
| Tier | Default Threshold | What Happens |
|---|---|---|
| Light | 6 | Mechanical health audit only (≤10% of full review cost) · releases 2-4 points · next medium/large demand waits for it |
| Full | 12 | Reviewer sub-agent + complete 4-phase audit · resets to 0-3 |
| Emergency | 20 | Demand intake halted · full review + blindspot root-cause + forced remediation plan |
Default numbers were calibrated from observing five actual review cycles. Too low causes frequent interruptions during build-intensive periods; too high makes each review an archaeology exercise. Thresholds also shift dynamically by project phase — build-intensive tolerates higher drift; quality convergence tightens. During a declared convergence phase, the emergency threshold tightens from 20 to 14 because framework-evolution noise is then pulling deliveries away from scoped debt. See drift.md §Review Tiering and ADR-12.
Mechanical floors (applied when scoring each delivery): the self-assessed score is bounded below by max(self_assessment, floor). ≥3 files → +2; ≥6 files → +3; ≥10 files OR new module/pattern → +5. Floors exist because self-scoring empirically skewed toward +1/+2 "honest underestimation." See drift.md §Rules.
Storage Shape — One File Per Event (ADR-22)
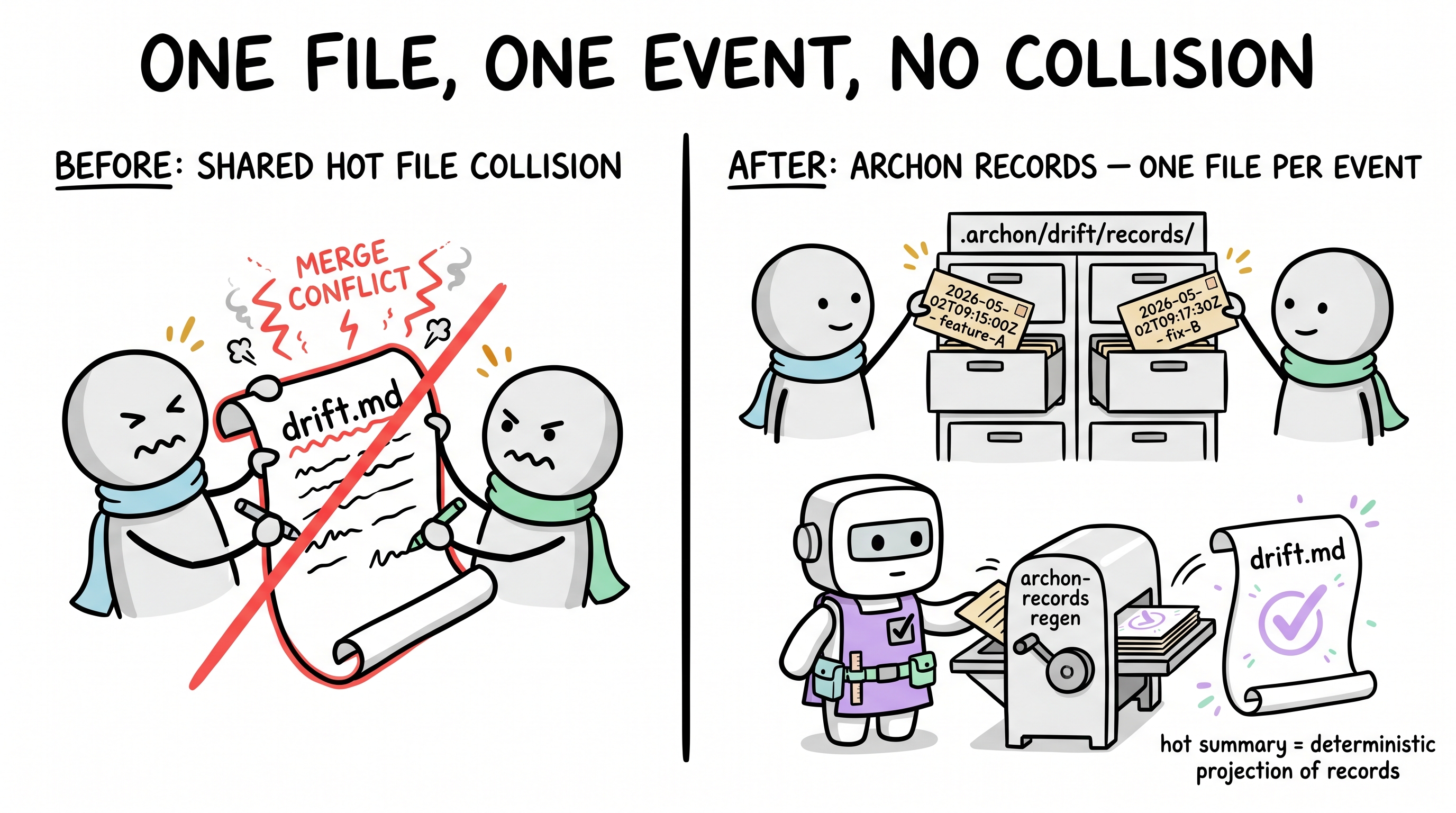
Earlier versions of this document described drift.md as a single append-only hot file. That mental model is still correct for reading — the hot summary is where an agent looks first. But writing to a shared append-only file collapses under concurrent cloud-agent deliveries: two branches appending at the same time guarantee merge conflicts that cannot be resolved mechanically.
Per ADR-22, the storage shape shifted to event-sourcing. Every completed delivery, memo, or debt item becomes its own immutable record file under .archon/drift/records/<ISO8601>-<slug>.md (parallel folders exist for memos and debt items). The hot summary (drift.md / memos.md / debt.md) is regenerated by scripts/archon-records.mjs; hand-editing the hot summary between sentinels fails validation. The drift counter becomes a commutative sum over records — parallel branches can write +5 and -3 independently and still converge to the same total after merge, without manual renumbering.
The progressive-loading discipline from ADR-21 (hot index + cold archive) is preserved: the hot summary is still a single fast read, records folders stay off the hot path, and quarter-folded archives still fold via merge=union. The only change is that the hot file is now a projection, not the source of truth. Snapshot state (manifest §Current State, §Convergence scope, §Latest review) deliberately stays outside records — those are "what is true right now," and parallel edits there are real semantic conflicts that need human resolution, not a CRDT.
Concurrency has two sides. Records-folder solves the governance-state side: two branches can each +5 / -3 their own drift records and still converge. ADR-29's Source Modularity Probe solves the source-code side at the Decision Gate: when a new file or a mapped path would fold a second concept axis into a file already responsible for one, the probe flashes fan-out-needed before any code is written, prompting either a prior split commit or an explicit map update. Together they remove both the event-append collision (storage-side) and the two-demands-editing-the-same-file collision (authoring-side). Neither probe blocks the Verdict — they make the structural fact visible so the owner's override carries explicit rationale.
Why Three Tiers, Not One?
The binary gate pathology: during build-intensive periods the single crossing is deferred (drift keeps climbing, review becomes archaeology); during quiet periods even trivial accumulations pay full review cost. Light review solves the first; fast-path (see soul/delivery.md §Delivery Fast-Path) solves the second.
The emergency tier exists because even a correctly-designed full-review gate can fail if it's enforced only at L3 (documentation). History proved this: drift reached 108% of full threshold while demands kept executing. The emergency tier is the circuit breaker — and ADR-9 promoted the pre-check itself from L3 to L1 (governance.test.ts) to prevent recurrence.
Reviews Are Not "Running Through a Checklist"
This is the part most easily done wrong.
If a review just means "open every file, tick boxes on a checklist," then it truly is a waste of time. You've spent tokens and time for false reassurance that "everything conforms."
Archon's review operates on two layers, solving different problems.
Layer 1: What Automation Can Do, Don't Do Manually
The validation gate runs lint + typecheck + test first. Issues catchable by machines (type mismatches, unused imports, failing tests) should never appear in a manual review report — they should be caught while you're writing code.
If your review reports are full of "this variable is unused" or "that type is wrong," it means your automated toolchain has gaps — not that the review is thorough.
Layer 2: What Humans (or Independent Agents) Do Is What Automation Cannot
The genuinely valuable parts of review are the things automation cannot infer from a single changed file:
- Architectural decay: Are inter-module dependencies silently turning into spaghetti?
- Abstraction soundness: Are there abstraction layers with only one implementation? Are any "utils" files bloating into junk drawers?
- Spec drift: Does what the code actually does still match what the manifest/spec files declare?
- Stagnation detection: Are the last five deliveries all fixing the same type of issue? If so, individual fixes are pointless — root-cause analysis is needed.
That last point is especially important. Reading the drift log isn't about knowing "what happened" — it's about discovering patterns. The same type of fix recurring = a systemic problem nobody is addressing. The log records symptoms; the review's job is diagnosing the disease from those symptoms.
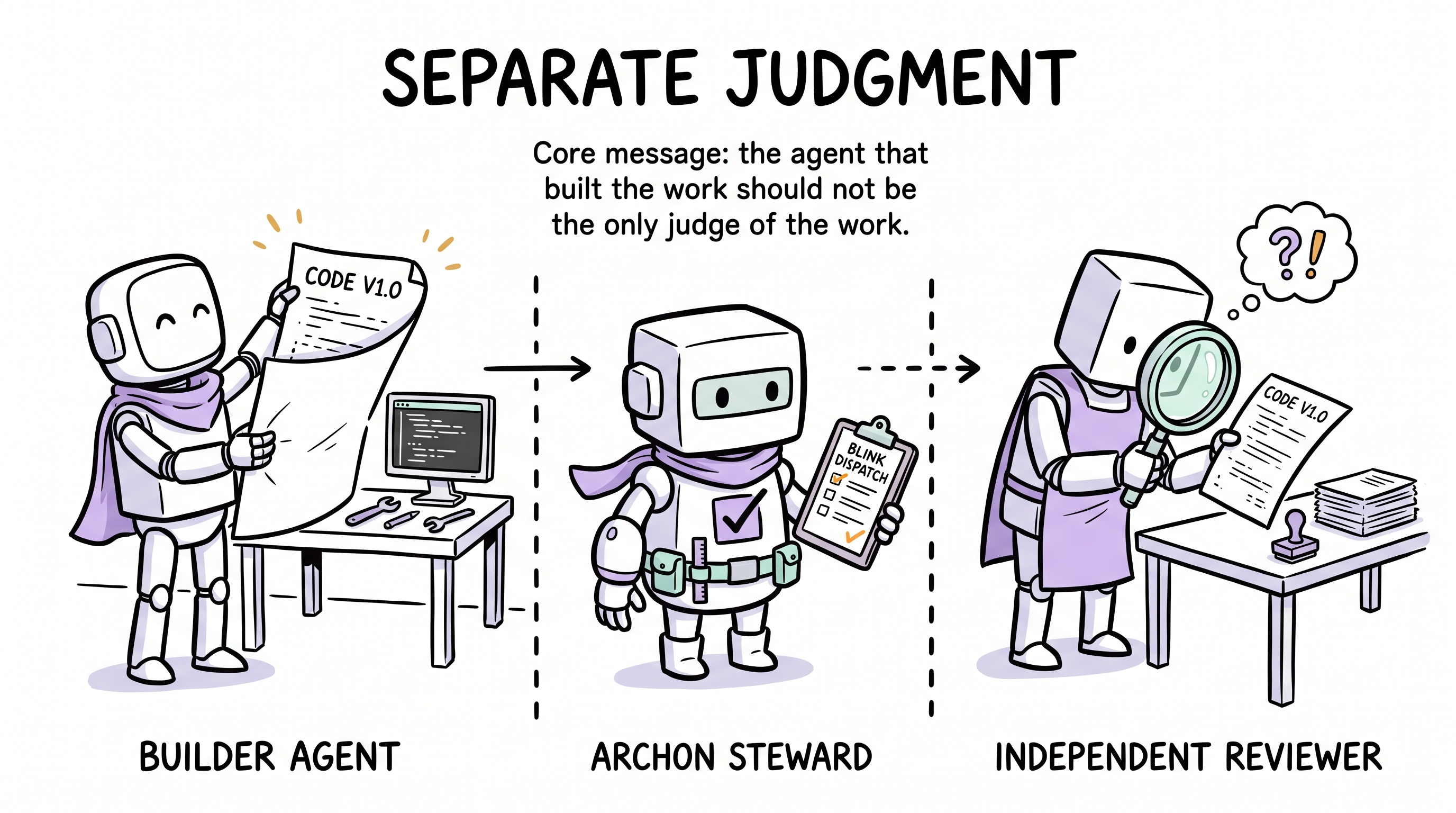
Why Reviews Must Be an Independent Sub-Agent
This is the least intuitive but most critical design decision in the entire mechanism.
You've written code all day, then you review your own code. What will you find? Almost certainly nothing. Not because the code is truly fine, but because of sunk-cost bias — your brain automatically rationalizes the thing you just invested heavily in.
This is true for human engineers, and equally true for LLMs. Within the same context window, the agent that generated the code will naturally lean toward "looks fine" when reviewing its own output.
Archon's solution is conditional separation of execution and judgment:
- The main agent writes the code
- Blink Dispatch thin-slices the completed diff before any sub-agent launch
- An independent reviewer sub-agent reviews it when drift reaches the full-review threshold — it didn't write the code, has no sunk cost, and no motivation to rationalize
- An independent capture-auditor sub-agent assesses post-delivery knowledge capture when Blink Dispatch detects implementation, governance, boundary, repair, state-closure, or uncertainty risk
Each additional sub-agent adds an LLM call's latency and cost. So not every step needs independent judgment — only those meeting any of these criteria:
- Judgment occurs after work completion (sunk-cost bias is strongest)
- Judgment has no self-correction mechanism (if wrong, no one catches it)
- Error cost is high (impacts correctness or architectural health)
Everything else stays as self-assessment. Be economical.
Knowledge Capture: Not "Record Something Every Time"

Archon's other sub-mechanism is post-delivery knowledge capture — Blink Dispatch first decides whether the delivery merits independent capture review, and the capture-auditor then determines whether it produced knowledge worth crystallizing.
The key word is "worth."
If you record something after every delivery, you'll quickly accumulate unread "experience notes." Knowledge bloat is more dangerous than knowledge gaps: the former gives the illusion of knowing, while the latter is at least honest.
Capture triggers are specific:
- Hit-a-wall pivot: Approach A failed, switched to B. What's worth recording isn't "chose B," but A's failure symptoms → root cause → B's derivation path — next time the same symptoms appear, reuse the proven path instead of re-deriving.
- Repeated pattern: Writing the same structure a second time. Time to abstract, not document.
- Concept discovered: A product-specific term appears that could be misinterpreted by its common dictionary meaning. Capture it in the manifest glossary — next session, the AI boots with the correct semantic frame instead of guessing.
- Stakeholder alias surfaced: The stakeholder keeps using a phrase, nickname, or indirect description ("那个覆面卡", "门户页") that points to an already-defined artifact. Capture it in the User Language Index instead of the glossary — the index maps wording to canonical targets (routes, files, components), and
/archon-demand §Pre-Scanconsults it on every demand so the agent never has to guess and the user never has to restate.

- Convention crystallized: An implicit convention keeps appearing in code. Time to make it a machine-enforceable rule, not a document.
And capture has priorities. What can be pushed to the type system shouldn't be a lint rule; what can be a lint rule shouldn't be documentation; documentation carries only "why" — this is the constraint pyramid, where higher levels have stronger enforcement and lower forgetting probability.
Preservation: The Second Motion of Evolution (ADR-28)
Capture — whether through drift signal, knowledge hit-a-wall, or reviewer finding — is only half of what evolution should do. The other half is preservation: actively protecting what already works so it cannot quietly be edited away.
Correction-only evolution has a specific failure mode. Every new cycle appends rules that fix the most recent failure. The rules that prevent the failures you never saw — the ones that explain why nothing else broke — depend entirely on agent memory. They have no mechanical anchor. One plausible refactor drains them silently. The trigger table cannot fire because there was no failure to observe.
Per ADR-28, preservation is the dual of crystallization:
- Crystallization asks: "What did this delivery teach that should change Archon?" → promote into a stronger vehicle (test, rule, skill, ADR).
- Preservation asks: "What did this delivery rely on that must not silently drain?" → pin the load-bearing anchor with a mechanical triple: an entry in the critical-rule registry, a body-shape test, and a portable-contract clause.
The Close-Out post-delivery review now requires both questions. The preservation answer is one of:
preservation: pinned(<anchor>+<test>+<contract>)— this delivery pinned a specific load-bearing anchor with all three mechanical guards.preservation: none-this-cycle(<evidence>)— this delivery scanned for load-bearing anchors and found none pin-worthy. The evidence must name the scan target and verb (e.g., "scanned soul §Imperatives 12 rows, all already pinned").
A preservation pin is a tripwire, not a wall. You can still remove a pinned rule — but the removal must be explicit (delete the anchor, the test, and the contract entry together), not a silent body-drain. That is exactly the difference between evolution and drift-toward-last-fix.
Evolution Tempo: Not Mode Flags, but State Inference
A common temptation is adding "modes" to the system — mode=build for rushing features, mode=harden for quality hardening.
This doesn't work. The reason is simple: who is responsible for switching modes?
If the AI decides, it will stay in "build" mode forever — because the backlog is never empty. If the user manually switches, the user needs to know when to harden, which violates "don't make the user make engineering decisions."
Archon's approach is inferring behavior from project state:
- Early in milestone, most acceptance criteria unchecked → bias toward feature delivery
- Features complete, quality gates failing → bias toward hardening
- Debt registry has Critical/Warning items nearing deadline → bias toward repair
- ≥3 of last 5 drift log entries are same-type fixes → stagnation signal — needs root-cause analysis
No config needed, no flags. The signals are already in the manifest and drift log — read them, don't add another abstraction layer.
Honestly, What This Mechanism Doesn't Solve
Any design article that only discusses advantages is being dishonest. Candidly, the drift mechanism has fundamental limitations:
1. It cannot replace architectural thinking.
Drift + review can discover "something's wrong here," but cannot discover "how should the overall system be designed." Review is diagnosis, not planning. You can't expect a periodic check to substitute for deep architectural thinking — that requires the plan mode's deliberate exploration, not the review mode's compliance checking.
2. Quantification is rough.
"medium = +3"? Says who? A medium delivery introducing a new state management pattern and a medium pure-UI delivery have completely different cognitive impact. The scores are a rough approximation of complexity — their value lies in the signal "it's time to stop and look around," not in the specific numbers.
3. Review quality depends on the reviewer's capability.
The reviewer is an LLM sub-agent. Its review depth is limited by the code volume that fits in the context window and its reasoning ability. For a small project with a few dozen files, it can achieve comprehensive inspection. But as the project scales, "full review" either becomes surface scanning or needs to be decomposed by module — that evolution path hasn't been implemented yet.
4. The "is it worth it" judgment in knowledge capture is inherently hard.
The capture-auditor is independent, lightweight, and driven by a fast model. It can check "are there new test files" and "are there duplicate patterns." But "does this delivery's insight have long-term reuse value" — that judgment requires deep understanding of project history and technology choices, which a lightweight sub-agent struggles with. In practice, most deliveries have a capture result of — (nothing captured). Whether that ratio is appropriate remains an open question.
So What Does It Actually Solve?
Strip away the mechanism details, and drift + review solves exactly one core problem:
In a session-based AI engineering environment, create a rhythm that forces you to stop and see the full picture.
Human engineers have code reviews, standups, and retrospectives for this. AI agents have no colleagues, no calendar, and no gut feeling that "something seems off." They need an externalized, quantified, unskippable trigger to break the infinite loop of "receive demand → write code → receive demand → write code."
Drift is that trigger. Nothing more, nothing less.
It doesn't guarantee high review quality — that depends on the reviewer protocol design and LLM reasoning capability. It doesn't guarantee correct knowledge capture — that depends on auditor judgment and crystallization path design. It doesn't guarantee architecture won't decay — architectural health requires proactive planning and deep thinking, not passive periodic checks.
It guarantees exactly one thing: you won't keep blindly delivering while your cognition has severely diverged from reality.
That one thing is already important enough.
This is part of the design notes series for the Archon engineering governance framework. Archon is a session-based AI engineering governance framework that runs inside pair-programming IDEs.