Strong Models Don't Need a Framework — Do They?
A recurring debate in the AI engineering community: Model vs. Harness. One camp argues model capability is growing exponentially and any framework is a redundant constraint — a harness that slows the thoroughbred down. The other argues that without a framework, even the strongest model only makes locally-optimal decisions. This note doesn't pick a side. It just asks a few questions.
Audience: skeptics, decision-makers evaluating whether to adopt Archon, and anyone who has ever thought "my model is strong enough, I don't need process." If you want the architectural answer rather than the philosophical one, read architecture.md.
The core claim is simple: models provide thrust, the engineering environment provides direction. Archon isn't about "restricting the model." It's about giving a strong model the right inputs, boundaries, and feedback.
The argument, stated plainly
"Models are getting stronger. GPT-5 can read 100k lines in one pass. Claude can decompose tasks and execute them autonomously. A year from now, your system prompts, rule files, and lifecycle hooks will all be redundant — the model will just know what to do."
This argument rests on a premise: the model's bottleneck is reasoning and coding. If reasoning is strong enough and code quality is high enough, engineering problems disappear.
We don't dispute the premise. Models really are getting stronger. But we question an implicit assumption:
Are engineering problems really rooted in "not smart enough"?
Six questions

None of the six questions below is about the model being insufficiently smart. What's missing is, in order: a vocabulary, a decision log, a stopping trigger, independent review, a historical pattern library, and a clear engineering role.
1. Even the strongest model — does it know your project's jargon?
Your product has a concept called "FaceDownCard" — a specific game mechanic with flip-trigger rules, scoring interactions, and a state machine. Your team invented the term.
You open a fresh session and tell the world's strongest model: "Add a flip animation to FaceDownCard."
What does it do?
It doesn't know what FaceDownCard means. It greps the codebase, finds three similar concepts (back-card, side-card, hidden-card), stitches together a Frankensteinian understanding — and picks the wrong one.
This isn't a reasoning problem. It's an information problem. The model doesn't lack the compute to calculate a flip animation; it lacks the semantic anchor that says "these three characters, in this project, mean that specific artifact."
Worse: three sessions ago the model itself created the FaceDownCard system (component FaceDownCard, state machine CardReveal, event flipTrigger). But the user doesn't remember the term, and describes it as "the card that starts face-down and flips over." The model now has to reverse-engineer: these 11 words → FaceDownCard. It can't even proactively ask, "Do you mean FaceDownCard?"
Because it has no shared vocabulary.
Reasoning doesn't solve this. A 1M-token context window doesn't solve it either — the vocabulary problem isn't about context length; it's about nobody telling the model what this term means in this project.
2. Even the strongest model — does it remember last week's veto?
Last week you debated whether to migrate to a new application framework. The conclusion: blast radius too large, the current milestone doesn't need a full-stack replacement, only a handful of pages are affected. Vetoed. The alternative was smaller, bounded optimizations.
New session. You mention the first screen is slow. The model's first reaction?
"I recommend migrating to a new rendering framework."
It doesn't know the proposal was vetoed last week. It doesn't know why. It doesn't know you already have an alternate path. It re-derives from scratch, reaches the identical conclusion it reached last week — gets vetoed again, and wastes 20 minutes re-explaining.
This isn't an IQ problem. An IQ-200 new hire on day one also doesn't know what last week's architecture review vetoed. They don't need a higher IQ. They need the meeting minutes.
3. Even the strongest model — does it know when to stop?
You and the model ship ten features back-to-back. The code is fast and clean. Every commit compiles, tests pass.
What you don't know: the third delivery introduced a new state management pattern. The fifth delivery introduced a different one. The seventh delivery quietly overrode the naming convention of the third. By the tenth, three state-management paradigms coexist in the codebase, with no single one declared as the standard.
Every delivery was locally optimal. The model did the right thing at every commit. But globally it's a mess.
Why? Because the model has no mechanism to "stop and look at the big picture." It has no colleagues, no calendar, no "wait, something feels off" instinct. Human engineers have code reviews, standups, retros. The model has none of those.
No amount of reasoning makes the model spontaneously say, "Hold on, let's do a full review first." It needs an externalized, quantified, un-skippable trigger to break the infinite loop of accept-request → write-code → accept-request → write-code.
4. Even the strongest model — can it audit the code it just wrote?
You spend a day writing an essay, then proofread it yourself. How many mistakes will you catch? Almost none. Not because your language skills are weak, but because of sunk-cost bias — your brain auto-rationalizes the artifact you just invested heavily in.
LLMs are the same. Within a single context window, the model that generated the code is naturally biased toward "looks fine to me" when reviewing it. Not because the code is actually fine, but because producer and reviewer are the same entity.
This isn't a capability problem. It's a role conflict. Even at AGI-level reasoning, sharing the context between author and judge = conflict of interest. Human companies never let the author do the final review. That's Engineering Management 101.
5. Even the strongest model — does it notice it fixed this bug last week?
Monday last week: a component crashed because of a missing null check. The model fixed it. Wednesday: another component of the same class crashed, same cause. The model fixed it. This week: a third component — same problem.
Three independent correct fixes. Zero root-cause analysis.
Because each fix was "a new problem" to the model. It has no mechanism to notice "this is the third occurrence of the same problem class." It doesn't think "maybe the issue isn't in a specific component but in the template or convention that created them."
A strong-enough model can flawlessly fix every individual bug. But fixing bugs and eliminating their root cause are entirely different things. The former needs reasoning; the latter needs pattern recognition — and pattern recognition requires a history to look at.
6. Even the strongest model — does it know when to push back?
You say, "Use Redis for caching." You're the product owner, not the architect. You said that because you read a Hacker News post praising Redis.
What does a "strong enough" model do?
- If its role is assistant — it executes. You're the boss. Three months later you discover your three-user MVP is running a Redis cluster with an ops cost higher than the rest of the app combined.
- If its role is engineering owner — it says: "At your scale, in-memory caching is sufficient. Redis introduces unnecessary infrastructure complexity. I don't recommend this."
Capability doesn't determine behavior — positioning does. A "strong enough" model can execute your bad idea or refuse it. The question is: what decides which one?
You're actually arguing about two different things
The "Model vs. Harness" debate recurs forever without resolution because participants conflate two completely different problem classes:
| Class | Nature of the problem | Can model capability solve it? |
|---|---|---|
| Reasoning problems | Code isn't good enough, design isn't optimal | ✅ Stronger model = better code |
| Environment problems | Missing context, missing memory, no self-oversight | ❌ No model can guess what you didn't tell it |
None of the six questions above is a reasoning problem. All six are environment problems:
- Jargon — information gap, not reasoning gap
- Veto memory — context discontinuity, not shallow thinking
- Global review — no trigger mechanism, not unwillingness to stop
- Self-audit — role conflict, not inadequate capability
- Pattern recognition — no history, not an inability to see patterns
- Independent judgment — ambiguous positioning, not lack of opinion
Reasoning capacity solves "how." The environment solves "in what context."
An IQ-200 genius thrown into an unfamiliar company — no project docs, no meeting minutes, no code review partner, no product glossary — will they do good work?
Yes. The code they write is top-tier. But they'll reinvent wheels, misread requirements, silently overturn predecessors' decisions, substitute generic terms for in-house jargon. Not because they're not smart enough — because no one gave them an environment in which they can function normally.
Harness or launchpad?
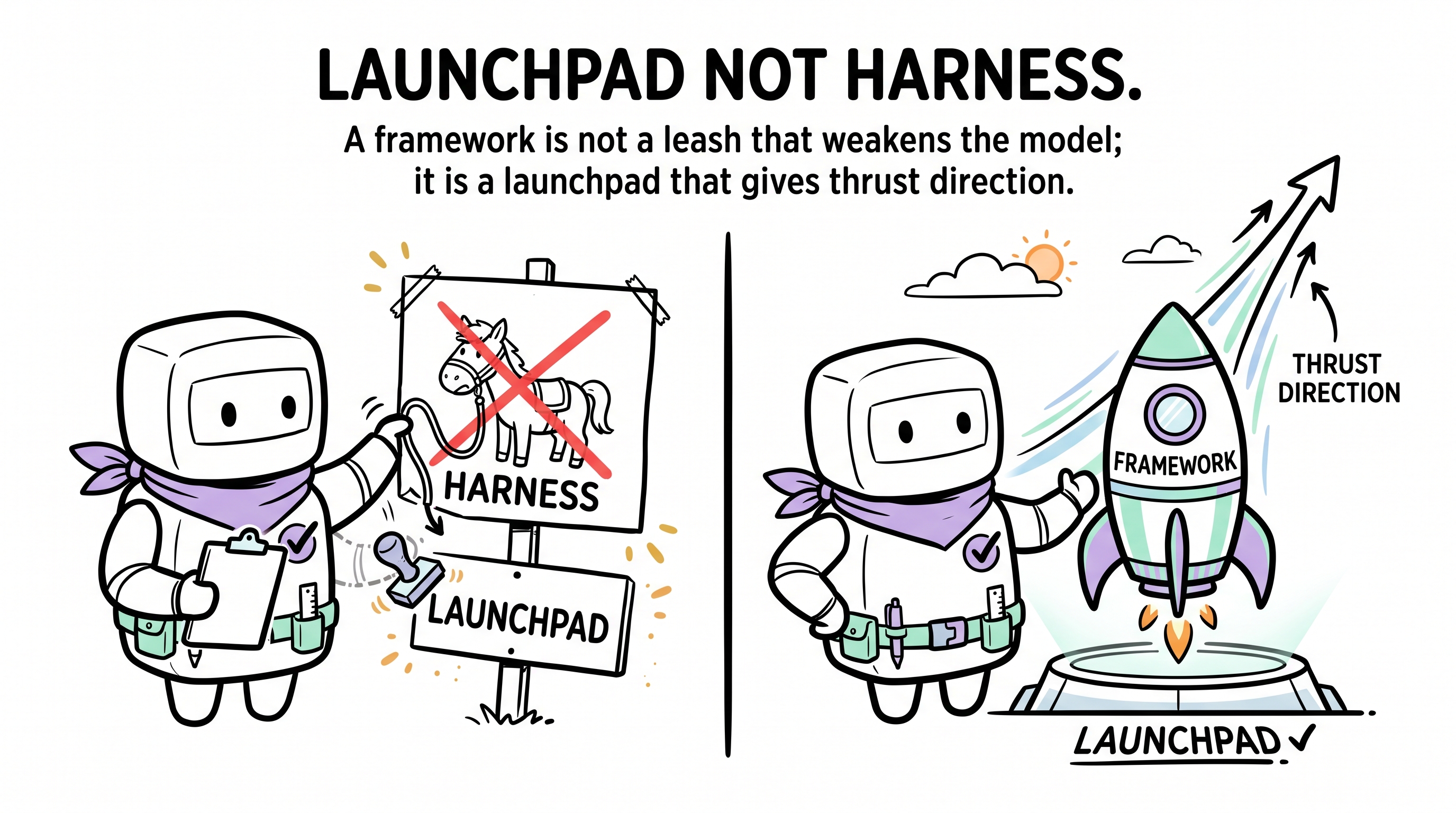
The word "harness" has a built-in negative connotation. Tack. Constraint. Restriction.
But consider:
The point of a harness isn't to make the horse run slower — it's to make the horse run in the right direction.
A thoroughbred without a harness may run a thousand miles — in the wrong direction. A horse running the right direction at a thousand miles a day is what has value.
That said, we think "harness" is itself misleading. It suggests the model is a wild thing to be broken. A more accurate metaphor: a launchpad.
A rocket's thrust comes from itself. Nobody doubts the engine. But before launch, the rocket needs:
- A coordinate system — where's the target? (project context, product definition, concept glossary)
- Orbital parameters — what constraints apply? (tech stack, architecture decisions, quality bars)
- A telemetry system — am I off course? (drift counters, periodic reviews, knowledge evolution)
- A separation mechanism — when to jettison the boosters? (execution/judgment split, sub-agent delegation)
A launchpad doesn't reduce thrust. It directs it. Remove the launchpad and the rocket still fires — it just spins.
What we chose
Archon is not a set of rules, not a pile of system prompts, not a collection of prompt-engineering tricks.
It's an engineering environment that addresses problems capability alone can't fix:
| What the model doesn't know | How Archon resolves it |
|---|---|
| A business term in this project is a lifecycle entity, not its everyday meaning | Manifest concept glossary, loaded every boot |
| You vetoed a large migration last week | Stakeholder memo scanned before every demand intake |
| After ten deliveries, the cognitive model has badly diverged | Drift counter + threshold-forced review |
| Self-reviewing one's own code = conflict of interest | Executor/reviewer split, delegated to independent sub-agent |
| The same bug class has been fixed three times without root-cause analysis | Knowledge evolution: trigger → capture → crystallize |
| Is the user expressing product intent or technical instruction? | Ownership model: the model is engineering owner, not assistant |
None of these mechanisms constrain reasoning — they feed reasoning with the right inputs.
A model that already knows "this business term is a lifecycle entity in this project" reasons far more efficiently than one that has to spend 2000 tokens archaeologically reconstructing that fact from the codebase.
A model that already knows "the large migration was vetoed last week" doesn't waste five minutes re-deriving a resolved question.
A model forced to stop for a full review every twelve deliveries doesn't unknowingly let three design paradigms coexist.
The environment isn't a constraint. The environment is what keeps reasoning from being wasted on things that shouldn't need to be reasoned about.
A thought experiment
Assume model capability reaches perfection — reasoning always correct, code always bug-free, architecture always optimal.
- Does it still need to know your jargon? Yes.
- Does it still need to know last week's technical decisions? Yes.
- Does it still need to be reminded "time to look at the whole picture"? Yes.
- Does it still need an independent role to review its work? Yes.
These needs don't vanish as the model strengthens. Because they aren't compensations for model weakness — they are intrinsic requirements of software engineering.
Human engineering teams have glossaries, minutes, code review, retros. Not because the engineers aren't smart, but because those are the infrastructure a collaboration system needs to run normally.
AI engineering just swaps "human-human collaboration" for "human-AI collaboration." The infrastructure requirements haven't changed. What changed is — now nobody remembers to build the infrastructure for the AI too.
So, Model vs. Harness?
This isn't an opposition.
Stronger model + right environment = stronger engineering output. Stronger model + no environment = a more efficient factory for technical debt.
The harness-camp mistake is reading "framework" as "limiting what the model can do." The truth is — a good framework expands what the model can do: it turns the model from "locally-optimal executor of the current request" into "engineering owner who understands the global context."
Models provide thrust. The environment provides direction. Neither is optional.
This document is part of the Archon engineering-governance design notes. Archon is a session-based engineering governance framework that runs inside AI pair-programming IDEs.
Further reading: user-journeys.md — 16 real cases showing how these environment problems surface and get resolved in practice. architecture.md — Archon's complete architecture.