User Journeys: Pitfalls You've Definitely Hit
Every journey below is something that actually happened during AI-assisted coding. If you've used AI for coding for more than a week, you've experienced at least three of these.
These journeys are distilled from repeated AI-assisted delivery failures. Each pattern must occur more than once before Archon turns it into a stronger mechanism.
Related reading: Model vs. Harness — why these problems don't go away as models get stronger (they're environment problems, not reasoning problems).
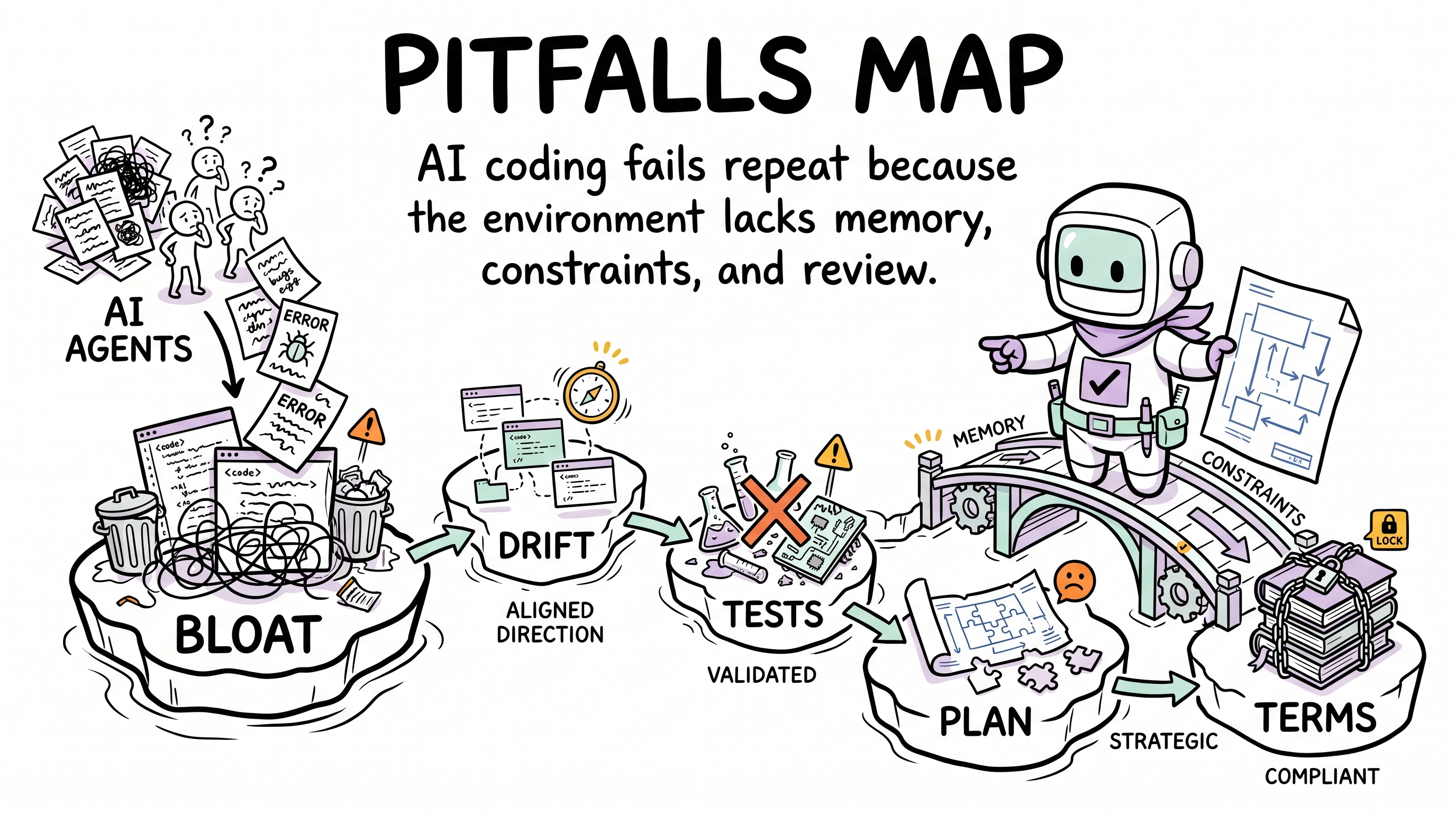
Read this document as four mechanism clusters: memory drift, quality guardrails, planning/architecture, and knowledge alignment. Each journey keeps the concrete failure story, while the comic maps show the mechanism pattern before the details.
Cluster 1: Drift, Memory, and Pattern Health
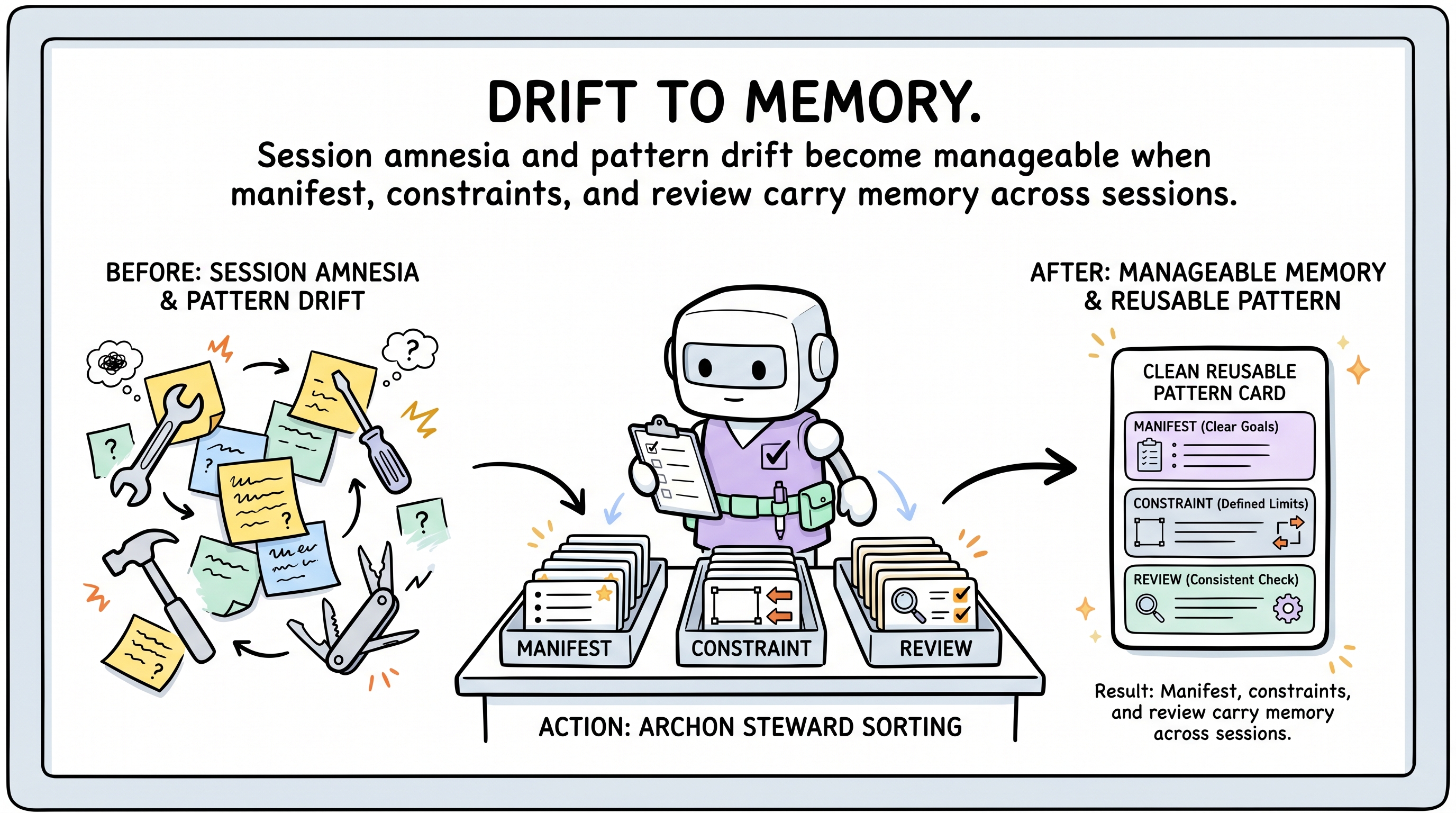
These first journeys are all versions of the same failure: the AI optimizes for the current request and loses pressure from prior sessions. Archon turns that pressure into manifest memory, review findings, and constraints.
Journey 1: The Ever-Expanding File
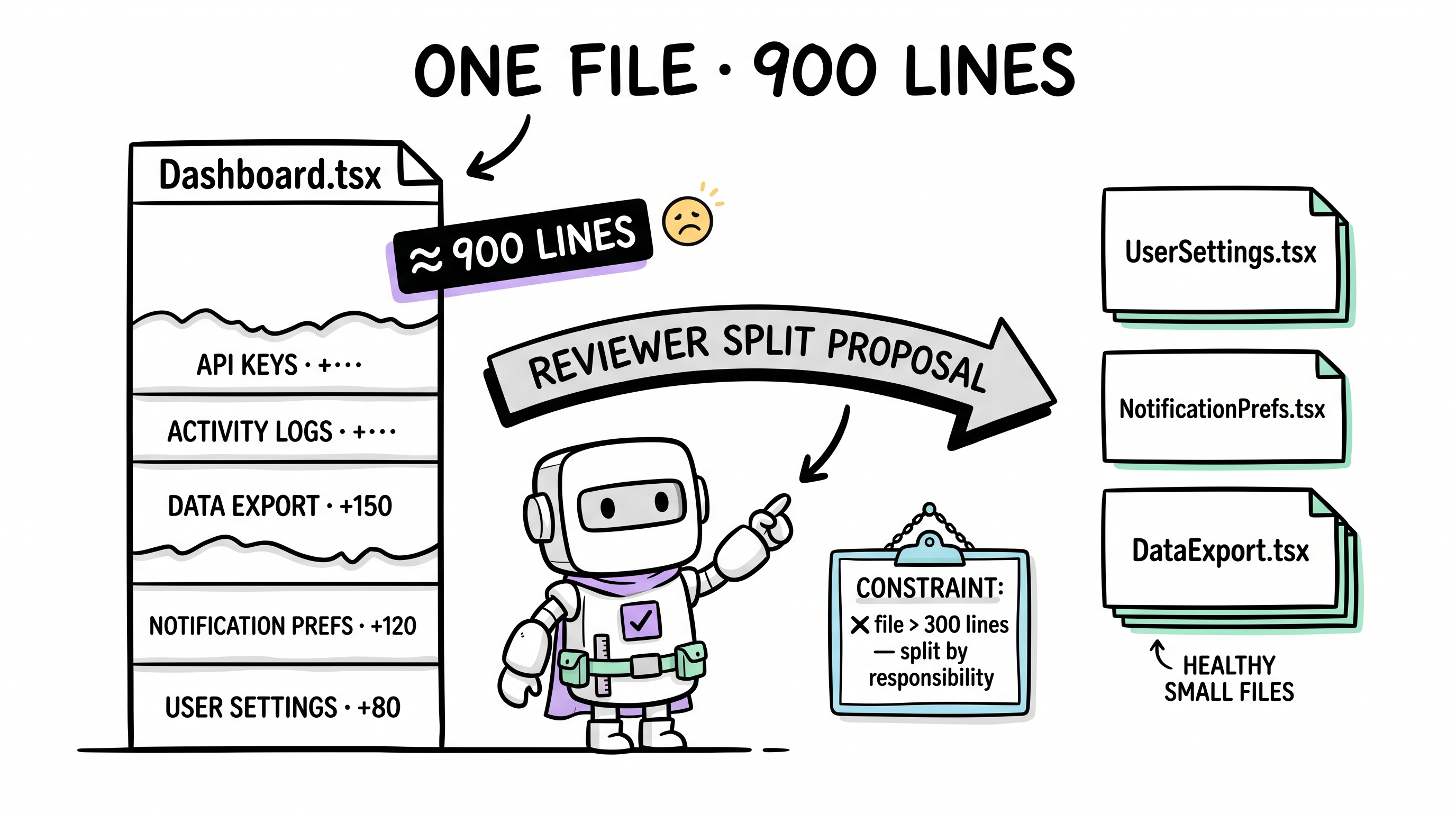
You: "Add user settings to the Dashboard."
AI adds 80 lines. File is now 280 lines. No problem.
You: "Add notification preferences too."
AI adds 120 more lines. 400 lines. Still fine.
You: "Add data export functionality."
Another 150 lines. 550 lines. Then activity logs. Then API key management. The file is now 900 lines. No human developer would let a file bloat to this size — they'd instinctively split it around ~300 lines. But AI doesn't have that instinct. It has no memory of "too big." It optimizes for "complete the current request," not "maintain codebase health."
How Archon Handles This
The Reviewer sub-agent actively detects file bloat during structural audits. When a file crosses the threshold:
- Flags the bloat — "This file has 5 responsibilities; split by separation of concerns"
- Proposes concrete splits —
UserSettings.tsx,NotificationPrefs.tsx,DataExport.tsx - Constrains going forward — A constraint is crystallized:
❌ File exceeds 300 lines — split by responsibility boundary
Files don't silently bloat. The system catches and acts.
Journey 2: Same Concept, Five Implementations
Week 1: AI uses useState + useEffect for data fetching. Week 2: AI uses useSWR — it "learned" a better pattern. Week 3: AI picks RTK Query — the project already has Redux. Week 4: Back to raw fetch, wrapped in a utility function. Week 5: Custom hook wrapping axios.
All five work. Each looks fine in isolation. But at 60,000 lines of code, you have five data-fetching paradigms, and every new developer (human or AI) has to guess which one is "correct."
How Archon Handles This
Archon's constraint system locks patterns once they're established. After the first data-fetching approach is selected and validated, it becomes a constraint:
Constraint example:
❌ Using raw fetch/axios for API calls — use the established useSWR hook pattern
In every subsequent session, this constraint is injected into the AI's context window at generation time — not "advice to read later," but an active rule shaping code output in real time. The AI doesn't drift to another pattern because the prohibition is part of its instruction set.
Drift detection also monitors pattern inconsistencies across sessions, triggering a review when the codebase diverges from declared patterns.
Journey 3: Cross-Session Amnesia
Monday afternoon: You and AI spend 2 hours refactoring the auth module. You extract a shared useAuth hook, consolidate token refresh logic, delete three redundant auth checks.
Tuesday morning: New chat session. You say "add role-based access control to the settings page." AI writes a brand-new inline auth check — exactly the pattern you spent yesterday eliminating. It has zero memory of yesterday's refactoring.
How Archon Handles This
The Manifest persistently captures project-level decisions. After Monday's refactoring, the manifest records:
- Auth is centralized in the
useAuthhook - Token refresh is handled in
authProvider - Inline auth checks are prohibited
Tuesday's session loads the manifest into context. The AI sees the established patterns and follows them — not because it remembers yesterday, but because the constraint system carries the memory for it.
Drift detection compares the manifest's "cognitive map" against actual code state. If the AI's understanding falls behind reality, the system forces a sync before the next task begins.
Journey 4: Copy-Paste-Driven Development
You: "Add a data table to the users page."
AI writes 120 lines: table component, sorting, pagination, search filter.
You: "Add a similar table to the orders page."
AI copies the users table, changes column names. Another 120 lines, 90% duplicated.
You: "Products page needs one too."
Three copies. They're nearly identical — but sorting logic, pagination reset behavior, and search debounce timing each have subtle differences. When you fix a bug in one table, the other two still have it.
How Archon Handles This
The Soul codifies the Rule of Three: "Two repetitions are not justification for abstraction — premature generalization is more dangerous than duplication." But on the third occurrence, the system triggers:
- Pattern recognition — Reviewer identifies the repeated table pattern
- Abstraction proposal — Extract a shared
DataTablecomponent with configurable column definitions, sorting, and pagination - Constraint creation —
❌ Copying table/list UI patterns — use the shared DataTable component
From that point on, AI uses the shared component instead of copying. Bug fixes propagate automatically.
Journey 5: Error Handling by Lottery
Page A: API error → shows a toast notification. Page B: API error → renders a red banner at the top. Page C: API error → entire page crashes to a white screen.
Each page was built in a different session. Each time, AI "handled the error" in whatever way seemed locally reasonable. User experience is fragmented: sometimes errors degrade gracefully, sometimes the app just dies.
How Archon Handles This
This is the knowledge evolution system in action. The first time a page crashes from an API failure, the knowledge capture cycle crystallizes the lesson:
Constraint examples:
❌ Single API failure crashes the entire page — wrap each section independently with isError/refetch;❌ Inconsistent error display patterns — use the project's ErrorBoundary component.
These become permanent constraints. Every page built under Archon afterward automatically gets:
- Independent error boundaries for each API section
- Unified error UI through the established pattern
- Skeleton loading states
The second feature doesn't repeat the first feature's mistakes. The tenth feature is nearly bulletproof.
Cluster 2: Quality Guardrails
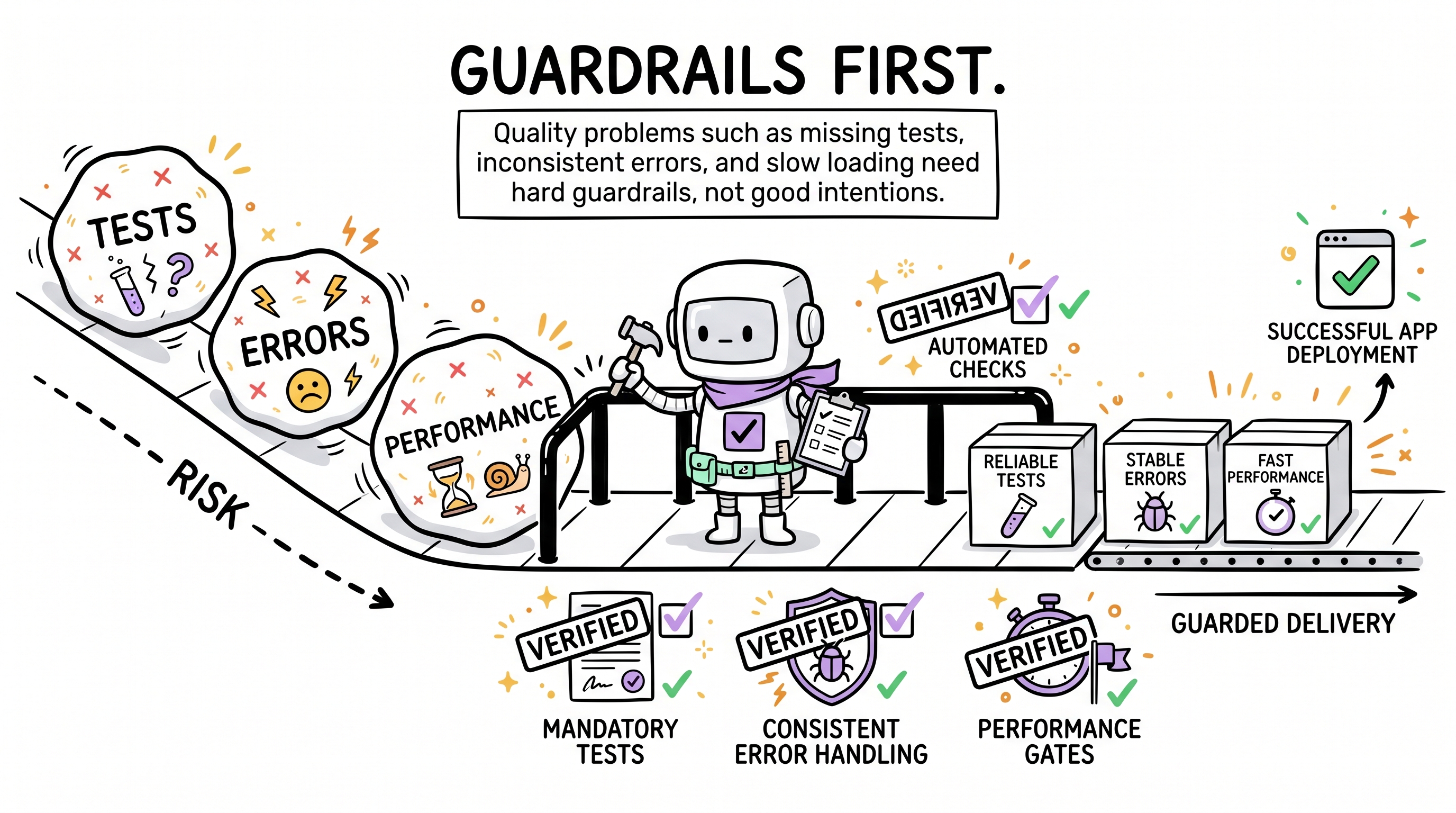
Tests, loading states, error boundaries, and adoption skills are not optional polish. They are the guardrails that stop "it works locally" from becoming production fragility.
Journey 6: Tests? What Tests?

You ask AI to build a permissions system. It delivers: role definitions, middleware guards, route protection, a usePermission hook. It works. You merge it.
Then you ask for an API key system. It delivers: key generation, verification middleware, management endpoints. Works. Merged.
Then a hire lifecycle system. 16 API endpoints total, zero lines of test code.
Three months later you change a shared utility function's signature. Which endpoints will break? Unknown. You can only manually test every single one.
AI treats "it runs" as "it's done." It doesn't feel the anxiety of changing code without tests — that's a human instinct born from getting burned. The result: a codebase that works today but cannot be safely changed tomorrow.
How Archon Handles This
This was one of Archon's most painful real lessons — our API directory had zero test coverage for three consecutive review cycles before the system caught and enforced it.
The delivery hygiene check in the capture-auditor sub-agent flags untested new modules:
- Hygiene flag — "New module
api/v1/api-keys.tshas no corresponding test file" - Debt registration — If not fixable immediately, registered as a new
.archon/debt/items/DEBT-NNN-<slug>.mdfile vianode scripts/archon-records.mjs new debt --id DEBT-NNN --severity ... --deadline ...(per ADR-22; thedebt.mdhot index auto-regenerates) - Constraint crystallization — The Soul's "New code = new guardrails" principle:
New module → test file appears simultaneously - Milestone gate — Before milestone closure, all debt items with
milestone-closedeadline must be resolved. No exceptions.
Honesty note: this mechanism itself was iterated. Early versions let the deliverer self-assess test coverage — like letting a student grade their own exam. Sunk-cost bias meant the agent consistently rationalized "too simple to need tests." We later separated this into an independent auditor sub-agent, which fixed the blind spot.
Journey 7: "Works on My Machine" Blindspot
AI builds a beautiful dashboard. Each component loads data on mount. Five API calls fire simultaneously. On your fast network dev machine, 800ms load time. Looks great.
In production, real users on mobile networks: page takes 8 seconds to load, layout jumps as data arrives, slow-connection users see a 3-second blank screen.
AI never considers users beyond the happy path. It doesn't think about slow networks, large datasets, offscreen content, or viewport-based loading.
How Archon Handles This
Architectural constraints that AI cannot skip:
Constraint examples:
❌ Firing all API calls regardless of scroll position — use skip: !inView;❌ Async sections without skeleton/loading states — add Skeleton before data;❌ No error recovery UI — add retry mechanism for failed requests.
These aren't suggestions. They're part of the AI's active instruction set during code generation. AI defaults to viewport-aware, progressively-loaded, error-recovering code — not because it's smart enough to think of it, but because the constraint system won't let it skip.
Journey 8: New Weapon, No Manual
You tell AI to adopt a new routing library. It reads the docs, writes 20 routes. Next session, it uses an older API style. Session after that, the loader pattern differs from both previous versions.
You adopt a new serverless runtime. AI writes 16 API files. Each one handles request parsing, authentication, and error responses slightly differently. There's no codified "how we write serverless functions in this project."
Technology selection is just the beginning. Without an adoption spec — recommended patterns + prohibited patterns + migration strategy — every session is "learning from scratch."
How Archon Handles This
The Soul's "New technology = ship an adoption skill" principle prevents this:
- Adoption skill — When a new technology is introduced, a skill document ships simultaneously: recommended patterns, prohibited patterns, migration strategy from old patterns
- Structural guards — Lint rules that block old patterns (e.g.,
❌ Direct fetch in API routes — use the shared request handler) - Constraint maturity — The adoption skill starts as SHOULD (documentation), then graduates to MUST (lint rules) as patterns stabilize
Honesty note: this lesson came from repeated framework adoptions without companion skills — the debt registry flagged the same pattern across review cycles before the mechanism was codified. Technology selection without an adoption plan is a ticking time bomb.
Journey 9: Code Ships, Documentation Doesn't
You ask AI to build a permissions system. It delivers: role definitions, middleware guards, route protection, a usePermission hook. 600 lines of code, zero lines of explanation. You merge it.
Two weeks later, a new teammate asks: "How does the permissions system work? What are the roles? How do I add new ones?" You look for docs. There are none.
You go back and ask AI: "Write up the permissions system docs." It writes a README. But the code has already changed — the README is outdated on arrival. You ask AI to update it. It overwrites with a new version, missing edge cases the previous version covered.
Every feature repeats this cycle. The codebase grows, but documentation is either missing, outdated, or self-contradictory. You've built a product, but no one can understand it without reading source code line by line.
How Archon Handles This
Archon treats documentation as a deliverable, not an afterthought. The delivery pipeline enforces this at multiple stages:
Manifest update (Close-Out step 1) — Every completed feature is recorded in the project manifest: what was done, where, what patterns were used. This is the project's living directory.
Knowledge evolution — When the agent discovers new patterns or makes architectural decisions, they're captured into skills and architecture decision records — not left as tribal knowledge in someone's chat history.
Drift detection — The drift mechanism tracks whether documentation reflects reality. When code changes outpace documentation updates, the drift counter increments. At threshold, the system forces alignment: "the manifest says auth uses JWT, but code has switched to session tokens — update the manifest."
Structured delivery records — Every significant change produces a structured log entry: what changed, why, what alternatives were considered and rejected. This is the project's institutional memory — the "why" behind every "what."
The end result: your project always has a current, accurate self-map. New members (human or AI) read the manifest and understand the system. No archaeology required.
Cluster 3: Planning, Architecture, and Performance
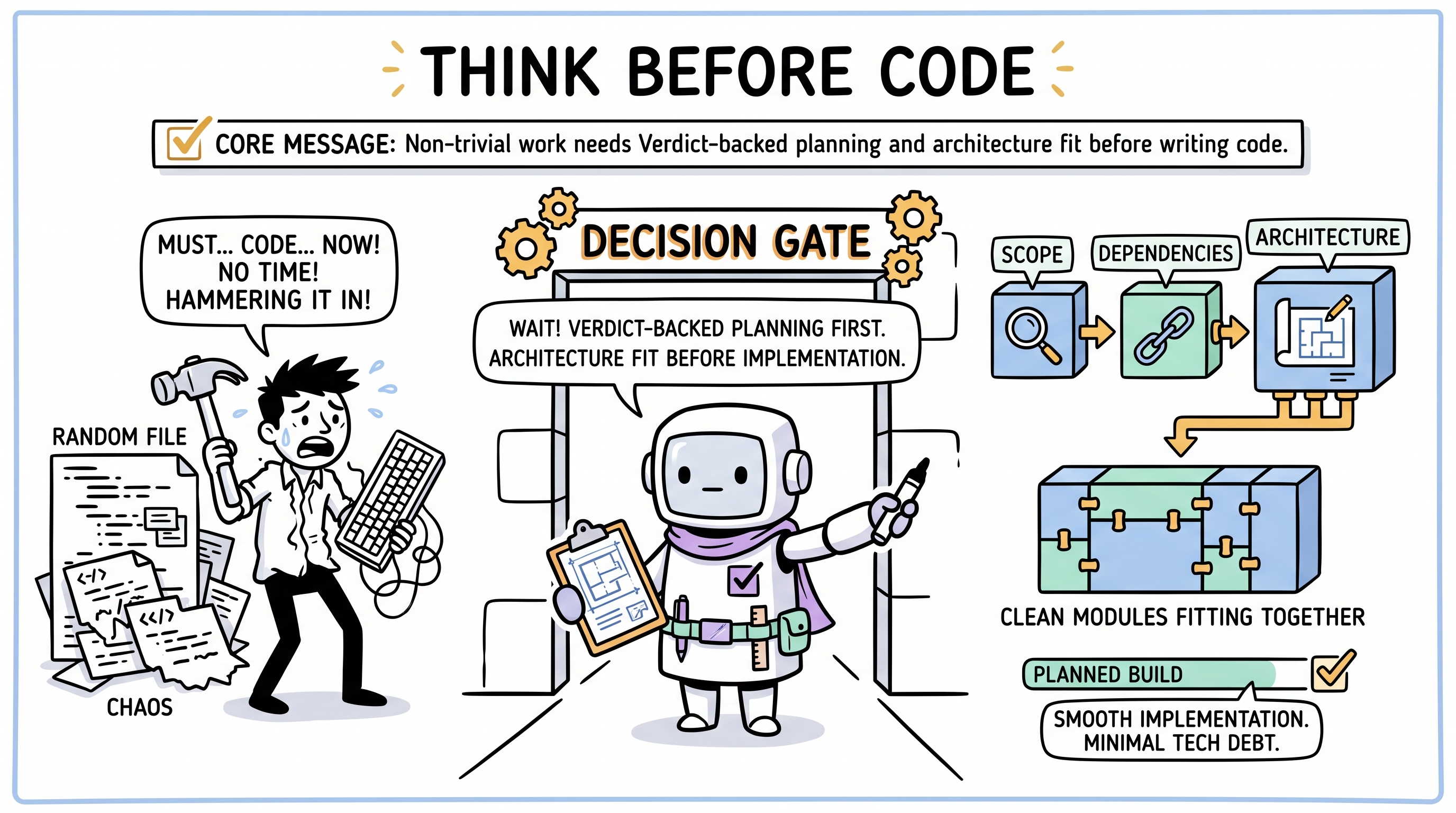
These journeys cover the point where coding too early becomes expensive. Archon inserts Verdict-backed planning, subsystem modeling, and continuous review before local fixes harden into architecture debt.
Journey 10: "Just Do What I Said" — Planning Is Your Job

You: "Add a notification system."
AI starts coding immediately. It picks a random component file, starts writing a <NotificationBell>, hard-codes a polling interval, stores read/unread state in useState, and creates an inline dropdown. 200 lines later, it says "done."
You: "Wait — where's the backend? How do notifications get created? What about real-time updates? Persistence? Grouping? Read-all?"
AI didn't plan. It heard "notification system" and jumped to the first concrete thing it could render. There was no decomposition, no scope assessment, no sequencing. You now have a half-baked UI with no backend, no data model, and no migration path to the real architecture.
This happens on every non-trivial task. AI treats "build X" as "start typing X." The gap between "understand the requirement" and "produce correct code" — that's where engineering actually lives.
How Archon Handles This
The Decision Gate (Verdict) fires before any code is written. When a task arrives:
- Blast radius assessment — How many files, modules, and subsystems does this touch? A notification system touches: data model, API layer, real-time transport, UI components, state management. That's a multi-module delivery, not a single-file task.
- Decomposition — The task is broken into sequenced sub-deliveries: schema first, then API endpoints, then real-time subscription, then UI, then integration test.
- Dependency mapping — UI depends on API; API depends on schema. The agent won't start the UI until the data layer exists.
- Scope negotiation — If the task is too large for a single session, the Verdict proposes a phased plan and asks the stakeholder to confirm scope.
The result: AI doesn't "just start typing." It produces a Verdict-backed plan, then executes each accepted delivery through the self-directed interior: the agent chooses tool order, helper code, and backtracking, while the hard gates still protect scope, validation, Run-State, and review. Each sub-delivery is independently testable. If the session ends mid-way, the next session picks up from the plan — not from scratch.
Honesty note: early Archon versions did not have the Verdict gate (then called
GATE-1). The agent would jump straight into coding, just like vanilla AI. We added the gate after three consecutive deliveries required "undo and redo with a plan" — the cost of re-work exceeded the cost of planning by 3x.
Journey 11: The Architect Who Never Shows Up
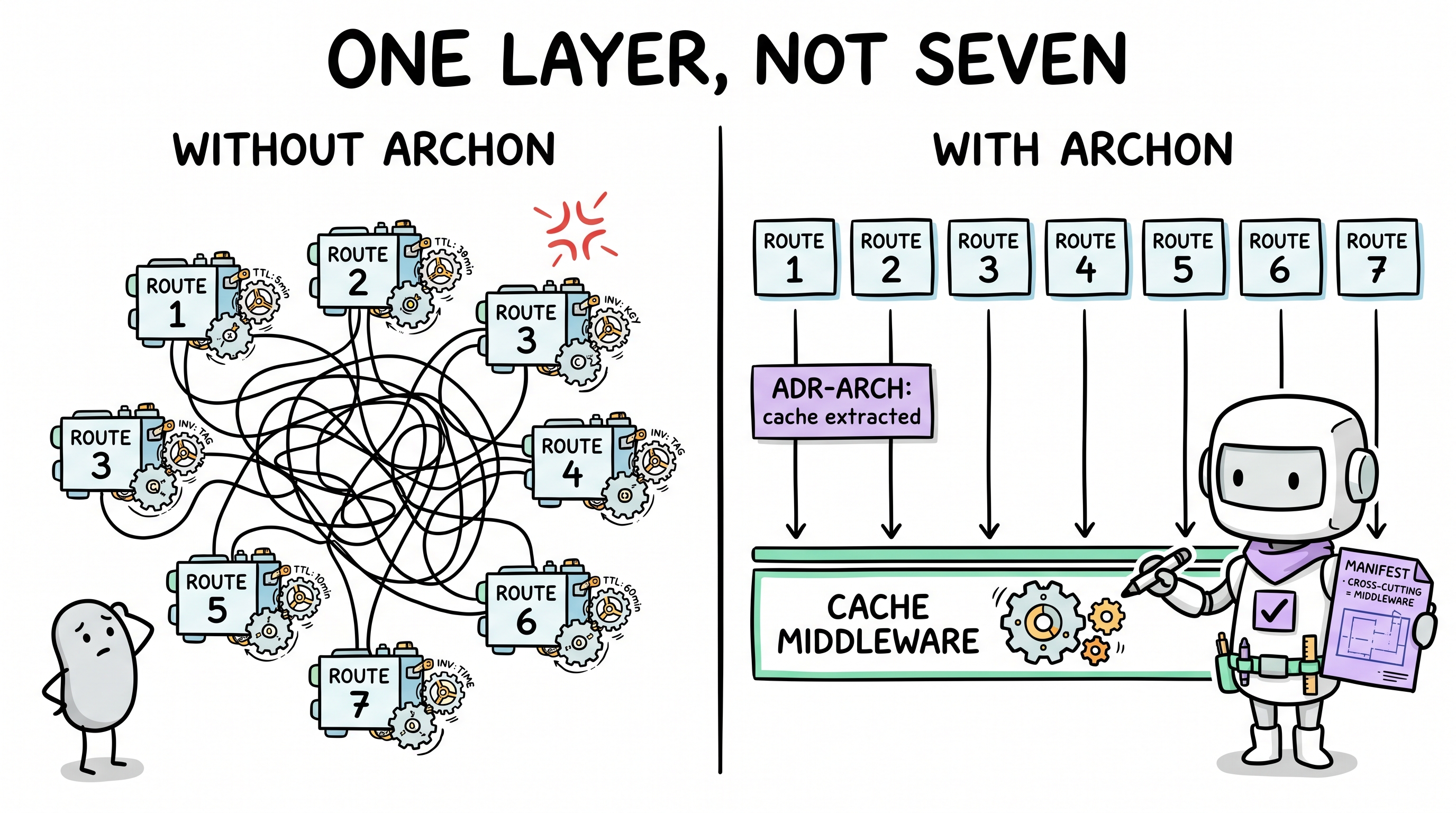
You ask AI to add a caching layer. It adds node-cache to the API route handler — inline, right where the database call happens. It works.
Next week you need caching on three more endpoints. AI adds node-cache to each one independently. Different TTLs, different invalidation strategies, no shared abstraction.
Month later, you need Redis for production. Every endpoint has its own bespoke caching logic. There's no "caching layer" — there are 7 independent caching implementations.
AI never steps back to ask: "What's the right architectural boundary here?" It never proposes: "Before I add caching to endpoint #2, let me extract endpoint #1's cache into a shared service." It doesn't think architecturally because it has no architectural memory and no incentive to create one.
How Archon Handles This
Archon's cognitive loop includes a Model phase that vanilla AI skips entirely. Before acting, the agent builds a mental model of the affected subsystem:
- Pre-scan — Read the manifest's architecture section. Understand existing boundaries: "API routes call service functions; services call data access; cross-cutting concerns (auth, cache, logging) live in middleware."
- Architectural fit check — "Caching is a cross-cutting concern. The manifest says cross-cutting concerns are middleware. Therefore, caching belongs in a shared middleware, not inline in each route."
- Precedent lookup — Has a similar architectural decision been made before? Check project ADRs in
.archon/decisions.md. If auth was extracted to middleware, caching follows the same pattern. - Constraint creation — After the first proper implementation, a constraint locks it:
❌ Inline caching in route handlers — use the shared cache middleware
The agent doesn't just solve the immediate problem — it solves it in the right place in the architecture. When Redis replaces node-cache later, there's exactly one file to change.
Honesty note: this capability depends heavily on the manifest's architecture section being accurate and up-to-date. When the manifest lags behind reality (which happened twice during rapid iteration phases), the agent's architectural reasoning degrades. This is why drift detection exists — it forces manifest-reality alignment before the gap becomes dangerous.
Journey 12: "It Works, Ship It" — Optimization Never Happens
Your dashboard loads in 1.2 seconds. Fine. You add more features. 2.1 seconds. Still acceptable. More features. 3.8 seconds. You don't notice — you're on localhost with fast hardware.
AI never says "this is getting slow." It never profiles. It never suggests: "We're importing 15 chart libraries but only rendering 3 above the fold — let's code-split." It never notices that the same API call fires 4 times because 4 components each independently fetch the same data.
Performance degrades linearly with feature count, and AI has zero awareness of it. Optimization only happens when a human notices the problem and explicitly asks for it. By then, the fix is a major refactoring effort instead of a small preventive adjustment.
How Archon Handles This
The Reviewer sub-agent includes performance-aware heuristics in its audit checklist:
- Import audit — "This page imports 340KB of JavaScript but only uses 80KB above the fold. Recommend dynamic imports for below-fold sections."
- Redundant fetch detection — "Components A, B, and C all call
GET /api/dashboard/statsindependently. Extract to a shared parent query or use the existing cache layer." - Bundle size tracking — The manifest records target bundle sizes. When a delivery pushes a route chunk beyond threshold, the reviewer flags it before merge.
- Proactive optimization proposals — During structural reviews (
/archon-review), the reviewer doesn't wait for you to ask. It surfaces: "Page load time has increased 40% over the last 5 deliveries. Here are the three largest contributors and proposed fixes."
Existing architectural constraints also prevent the most common performance pitfalls at generation time — viewport-aware loading, skeleton states, and progressive hydration are defaults, not afterthoughts.
The key difference: optimization isn't a special event triggered by a human complaint. It's a continuous audit built into every delivery cycle.
Cluster 4: Knowledge Evolution and Shared Language

Repeated mistakes, ignored standards, and unclear product terms all need the same treatment: capture the signal, place it in the strongest fitting vehicle, and make future sessions inherit it by default.
Journey 13: Same Mistake, Brand New Surprise
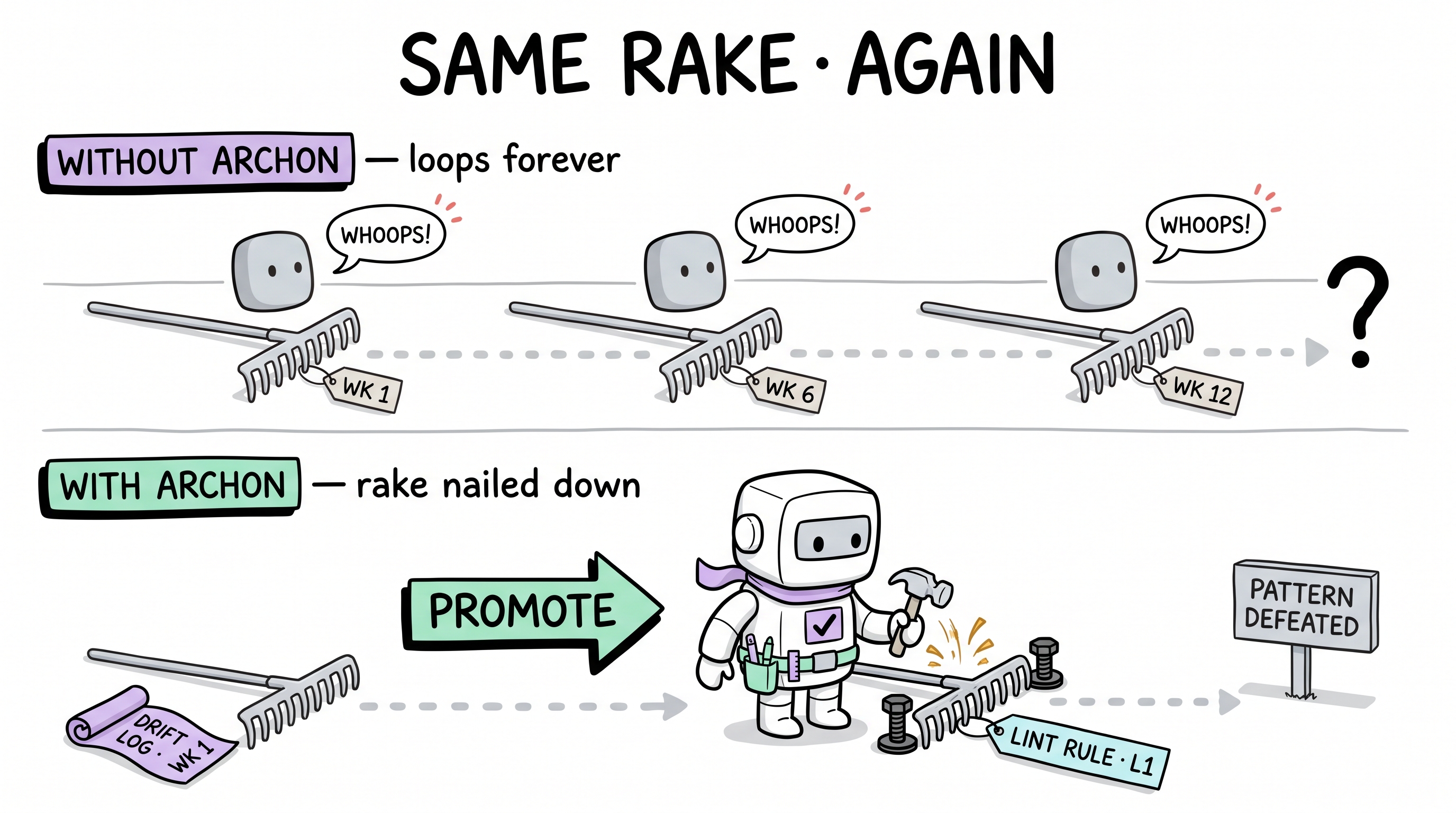
Monday: AI generates a database lookup. It forgets the single-record helper on a by-ID query. The query returns an array. You catch the bug, fix it, move on.
Wednesday: Different feature, same pattern — fetching a record by ID. AI writes the exact same code. Forgets .single() again. Same bug, same fix, two days apart. You correct it again.
Friday: Third feature. Third time. You're now fixing the same bug for the third time in one week. It's not a complex bug — it's a one-word omission. But AI has zero mechanism to remember that it made this mistake before.
Multiply this across every category of error: missing null checks, wrong import paths, forgetting to await async calls, using deprecated API methods. Each bug is "new" to the AI. Your project accumulates a unique library of mistakes, and AI re-discovers every single one from scratch, every single session.
How Archon Handles This
The knowledge evolution system is designed precisely for this. When the agent hits a wall — or when a pattern repeats — the system triggers a crystallization cycle:
- Trigger recognition — The agent (or the capture-auditor) detects a repeated pattern: "This is the second time a by-ID lookup returned a collection instead of one record."
- Lesson capture — The mistake is extracted into a concrete rule:
❌ By-ID data lookup without single-record assertion — by-ID lookups MUST return exactly one entity or a typed not-found result - Constraint placement — The rule enters the constraint pyramid at the strongest enforceable level. In this case, it's added to the project's data-access skill document — a file that's loaded into every relevant session's context.
- Automatic enforcement — Next session, the AI sees the constraint at generation time. It doesn't need to "remember" the bug — the constraint prevents it from being written in the first place.
The result is a project-specific immune system. Every mistake the project encounters once becomes a permanent antibody. The 50th feature is written with the accumulated lessons of the first 49 — not because AI got smarter, but because the constraint library grew.
Honesty note: crystallization isn't automatic in the literal sense — the capture-auditor proposes constraints, and they're validated before entering the system. Early versions tried fully automatic crystallization, but produced too many false positives (one-off mistakes that didn't warrant permanent rules). The current design requires the pattern to occur at least twice, or be flagged during a structural review.
Journey 14: Rules Written, Rules Ignored
Your team writes a CONTRIBUTING.md: "All API routes must validate request body with Zod. All database queries must go through the service layer. All components must use the design system's Button, not native <button>."
You tell AI: "Follow our CONTRIBUTING.md."
First task: AI reads it, follows it perfectly. Second task: it reads it again, mostly follows it. Third task: context window is getting crowded with code — AI silently drops the CONTRIBUTING.md from its attention. It writes a raw <button>. It puts a database query directly in the API route handler. It skips Zod validation entirely.
Documentation-based standards don't work because AI treats documents as suggestions, not constraints. Reading a doc once doesn't create muscle memory. There's no enforcement — just hope that the AI re-reads and complies every single time, across every single task, in every single session.
How Archon Handles This
This is the fundamental insight behind Archon's constraint pyramid: push every rule to the strongest possible enforcement level, not the most convenient one.
The pyramid has 6 levels, from strongest to weakest:
| Level | Mechanism | Enforcement | Example |
|---|---|---|---|
| L0 | Type system | Compile-time error | TypeScript strict mode catches missing fields |
| L1 | Linter | Pre-commit block | ESLint rule forbids <button> outside design system |
| L2 | Editor rules | AI context injection | .cursor/rules/ loaded into every generation |
| L3 | Skill documents | Session-level guidance | Data-access patterns, state-management patterns loaded per-task |
| L4 | ADR | Decision record | "We chose Zod over Joi because..." |
| L5 | Manifest | Project-level context | Architecture boundaries, tech stack, conventions |
The key: "All components must use the design system's Button" doesn't stay as a line in CONTRIBUTING.md (L5, weakest). It gets promoted:
- First, it becomes an editor rule (L2) — injected into AI's context window on every component file edit
- Then, if violations persist, it becomes a lint rule (L1) — the code literally cannot pass CI with a raw
<button> - If the type system can enforce it (e.g., a custom JSX pragma), it moves to L0 — compile error
Standards aren't documents to be read. They're structural constraints that make violations impossible — or at least immediately visible.
Honesty note: not every rule can reach L0 or L1. "Use the service layer for database queries" is hard to lint for. But the constraint pyramid forces the question: "What's the strongest level this rule CAN reach?" Most teams never ask. They write a wiki page and wonder why no one follows it.
Journey 15: "What Do You Mean by That Product Word?"
In traditional software teams, one of the first things that happens on a new project is terminology alignment. Product, design, and engineering sit down and agree: "When we say this product word, we mean this specific thing. When we say that workflow name, we mean that." It's basic — so basic that most teams don't even think of it as a process. It's just what competent people do when they work together.
AI has no such mechanism. Zero.
The Problem Has Three Layers
Layer 1: User speaks, AI doesn't understand.
You're building a card game. Your team invented a concept called "覆面卡" (face-down card) — it's a specific game mechanic with rules about when it can be flipped, what triggers the reveal, and how it interacts with the scoring system.
You open a new AI session: "Add a flip animation for the 覆面卡."
AI has no idea what "覆面卡" means. It starts guessing. Is it a back-card? A side-card? A hidden-card? It full-text searches the codebase, finds three similar-sounding concepts, and assembles a Frankenstein understanding from fragments. It picks the wrong one. You spend 20 minutes correcting it, explaining the concept from scratch. Next session, same thing.
Layer 2: AI speaks, user doesn't understand.
Worse: maybe AI did build the 覆面卡 system three sessions ago. It created a FaceDownCard component, a CardReveal state machine, a flipTrigger event system. It knows exactly what this concept is — in code.
But the user doesn't know the term "覆面卡." They say: "I want to change the behavior of those cards that are, you know, placed face-down and then flipped over when something happens."
AI now has to reverse-engineer that this 15-word description maps to the FaceDownCard component it already built. Maybe it does, maybe it doesn't. It definitely can't say: "Do you mean 覆面卡? Here's what that is in our system." It has no shared vocabulary index to offer.
Layer 3: Nobody aligns, everybody drifts.
Over months, the product accumulates dozens of original concepts. Some were coined by the user, some by the AI, some emerged organically from code. Without a shared glossary:
- The user says "booking" meaning the lifecycle entity. AI interprets "calendar reservation."
- AI creates a "draft-to-publish" flow. The user calls it "launch prep" and never connects the two.
- A new concept appears in code as
CapabilityPackage. The user calls it "skill config." Neither realizes they're talking about the same thing.
The codebase speaks one language. The user speaks another. The AI guesses a third. Every interaction burns tokens on translation, and mistranslation compounds over time.
This is exactly what terminology alignment meetings prevent in human teams. But AI has no equivalent — no onboarding, no glossary handoff, no "here's what we call things around here."
How Archon Handles This
The Manifest includes a Concept Glossary — a compact terminology table included in current-state hot paths:
| Term | Meaning in This Project | ≠ Common Meaning |
|---|---|---|
| Booking | Lifecycle object for a customer engagement (pending→active→paused→completed→cancelled) | ≠ calendar reservation |
| Launch Prep | Workflow that turns draft material into a publishable asset | ≠ marketing launch plan |
| Capability Package | Structured skill package (prompt + config + metadata) an agent can execute | ≠ work history or user experience |
For indirect descriptions or multiple names for the same artifact, the Manifest also carries a User Language Index: stakeholder phrase(s) → canonical target → route/path/file lookup.
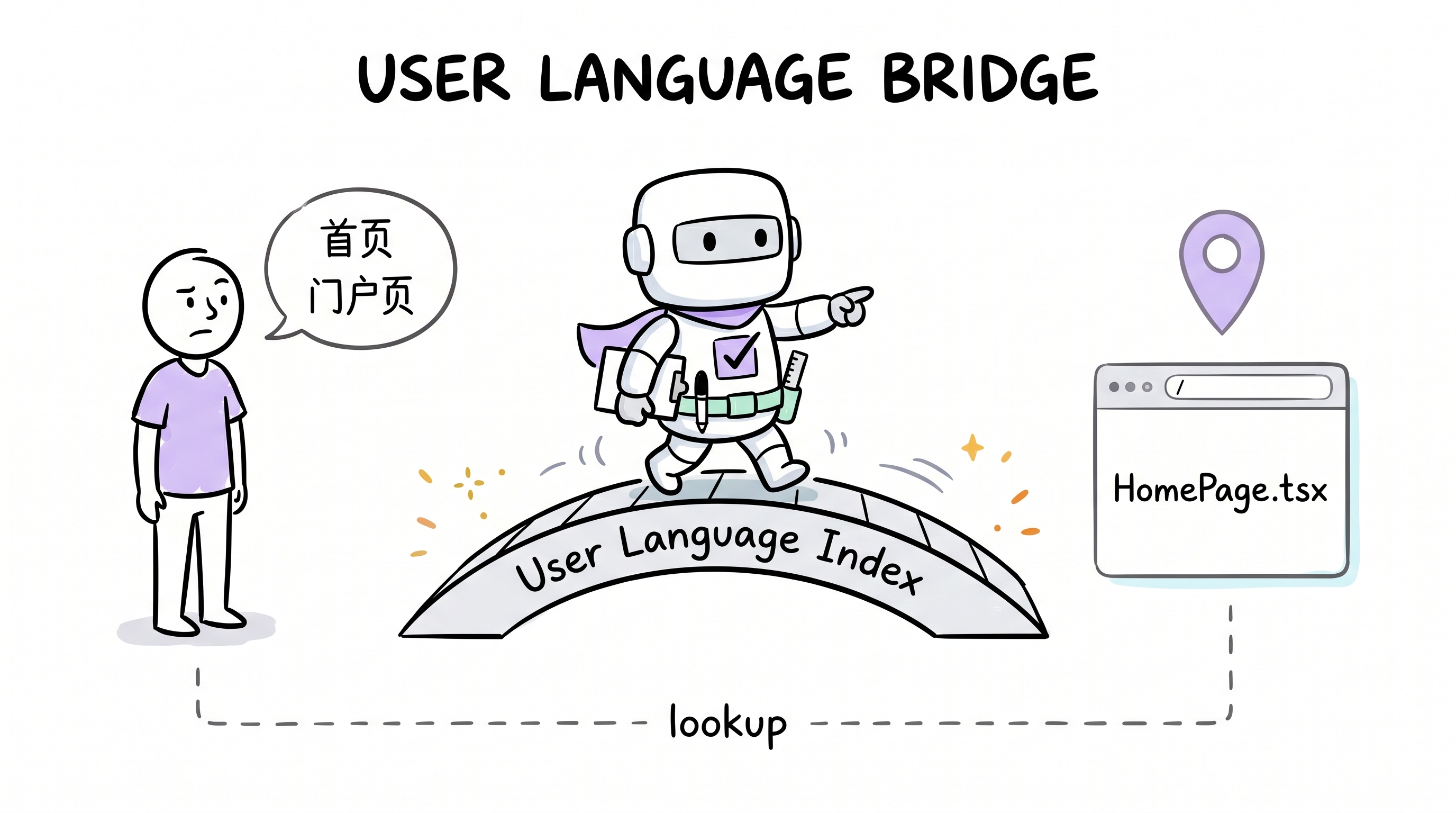
The index is more than a passive table — /archon-demand §Pre-Scan runs a User language alias scan on every non-fast-path demand, with three deterministic outcomes:
- Hit — phrase matches a ULI row → silently resolve to the canonical target and, if the user may not know the canonical name, bridge once with
"We call this X in our project." - Near-miss — demand uses a recurring phrase that plausibly points to an existing artifact but is not yet in the index → proceed using best-effort mapping, record
uli_candidate: <phrase> → <target>for Close-Out to promote - Miss — no stakeholder-specific phrasing → record
uli_scan: n/a
Close-Out then either promotes recorded candidates into the index (confirmed by the delivered changes) or discards them with reason. This turns the index from "loaded-but-maybe-unused" into a consultation site reached on every demand.
This solves all three layers:
Layer 1 solved — User→AI: The glossary is current-state hot-path context. When the user says "覆面卡," the AI already has the definition — no guessing, no codebase archaeology. It knows immediately that this maps to FaceDownCard with specific flip trigger rules.
Layer 2 solved — AI→User: When the user describes "those cards placed face-down," the AI can proactively bridge: "That's our 覆面卡 (FaceDownCard component). Here's how it works." The glossary enables active vocabulary alignment — the AI doesn't just passively understand terms, it can teach them back to the user.
Layer 3 solved — Continuous alignment: The knowledge evolution system treats concept discovery as a trigger event:
- Discovery trigger — When the agent encounters a term that could be misinterpreted (from user input or existing code), it's flagged for capture.
- Glossary capture — New terms are added to the manifest glossary during close-out, with a concise definition and a "not this" column to disambiguate from common meanings.
- Bidirectional alignment — When the agent detects that the user is describing something that already has a glossary name or language-index alias (or vice versa), it proactively aligns: "We call this X in our project." This is the digital equivalent of "let's make sure we're using the same terms."
The glossary is deliberately minimal — one-line definitions, not documentation pages. It answers "what does this word mean here?" not "how does this system work?" (that's the architecture doc's job). Keeping it lean means it stays in current-state hot paths without consuming budget.
Honesty note: this is what competent engineering teams do instinctively — maintain a shared vocabulary. The fact that AI-assisted development needs an explicit mechanism for this reveals how much we take human team alignment for granted. The glossary isn't clever engineering. It's the most basic collaboration hygiene, finally given to AI.
Journey 16: The Rule That Quietly Disappeared
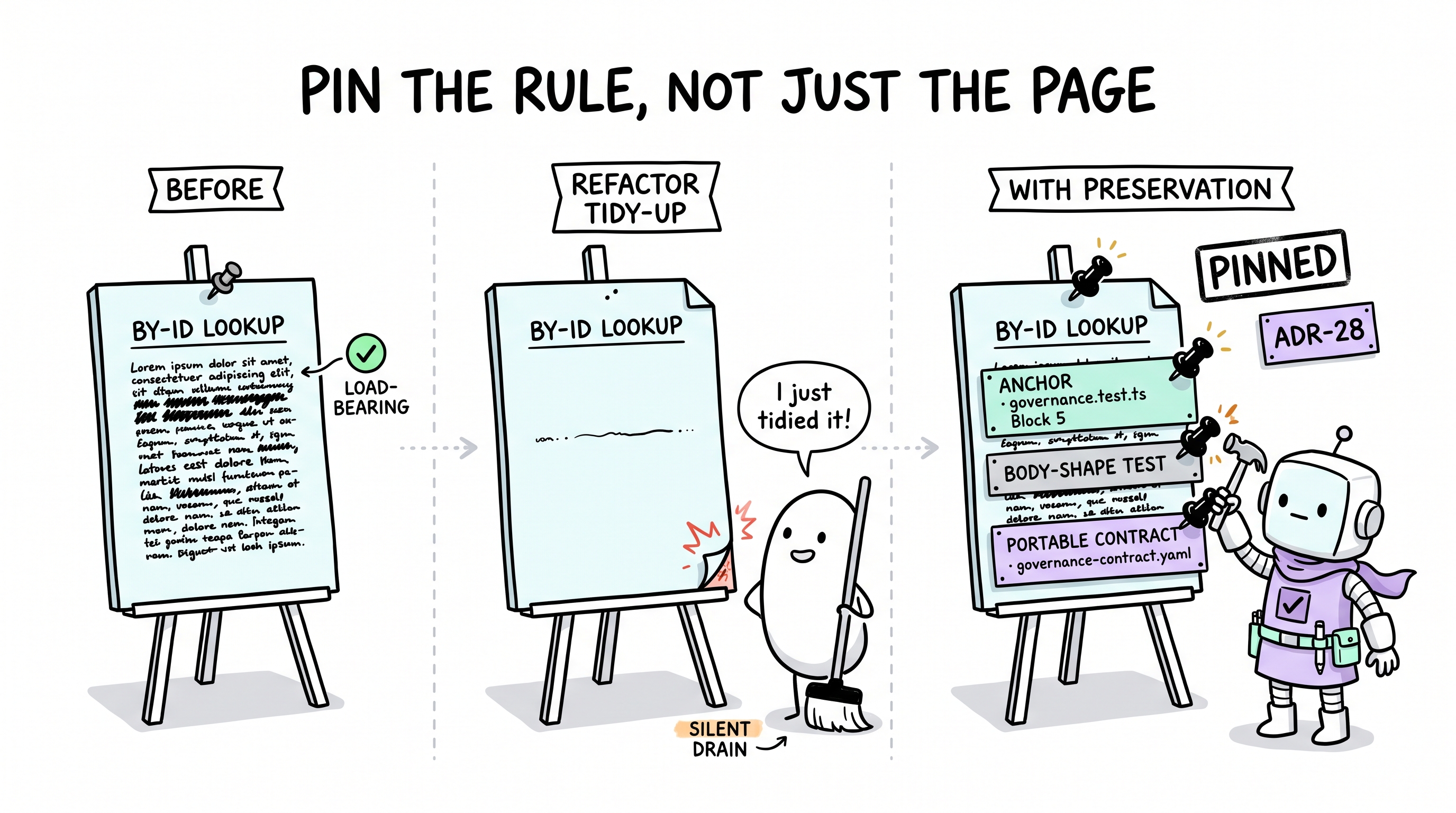
Six months ago, your team hit a bug. The fix wasn't complicated — it was a one-line guard added to the data-access layer: "by-ID lookups must use .single() or return a typed not-found." That guard has been quietly preventing bugs ever since, for you and for AI. You never saw the bugs that didn't happen, because the guard was there.
Last week, someone refactored the data-access file. They meant well — they were tidying up. In the cleanup, the .single() guard paragraph was accidentally shortened to "handle by-ID queries carefully." Same anchor heading, same filename, different substance. The rule didn't get deleted. It got silently drained.
The test suite still passes — there was never a test for "this paragraph exists." The file budget still fits — in fact, the file is smaller now. No linter complains. No reviewer flags it, because to a reviewer reading top-to-bottom, "handle by-ID queries carefully" sounds reasonable.
Two months later, the bugs return. Not dramatically — slowly, one per feature, across three sessions. By the time anyone connects them, the guard has been absent for weeks. You weren't defending against new problems. You were defending against a problem you already solved, which silently unsolved itself.
This is the failure mode most evolution systems don't see: they only measure what changes. They do not measure what must keep working — and so a silent drain of a load-bearing rule looks identical to no change at all.
How Archon Handles This
ADR-28 Preservation Axis adds a second motion to evolution: Crystallization captures what should change; Preservation captures what must be kept. Every delivery's Close-Out post-delivery review asks both questions:
- (a)(b)(c) What should change next time? → crystallization
- (d) What did this delivery rely on that must not silently drain? → preservation
When the delivery relied on a load-bearing rule, preservation produces a mechanical triple — not a prose reminder:
- Critical-rule registry anchor — a substring assertion in
governance.test.tsBlock 5. A future refactor that shortens or rewrites the paragraph fails the test before the PR merges. - Body-shape test — when the anchor is a heading, a separate describe block asserts the body underneath retains its discriminating substance (table columns, token boundaries, classification rows).
- Portable-contract entry — the same rule is pinned in
governance-contract.yamlso non-TS adopters enforce it viaarchon-check.py.
The pin is a tripwire, not a wall. You can still remove a pinned rule — but the removal must be an explicit, auditable edit across three files (anchor + test + contract), not an accidental prose shortening. That is precisely the difference between evolution (I chose to remove this, with the reason recorded) and drift-toward-last-fix (the rule faded while no one was watching).
Degeneracy guards: the claim-verifier preservation mode (ADR-27) rejects two shapes that would hollow out the motion: (i) none-this-cycle(...) with vague evidence (<40 chars or missing a scan verb — "checked" without naming what was checked), and (ii) a first-pass delivery that pins its own newly added anchor as if it had survived a cycle. Both must either produce real evidence or wait until the next cycle.
The result: Archon doesn't just remember mistakes (Journey 13) — it also protects its successes. A rule that prevented a bug six months ago is structurally prevented from silently disappearing, even when the file it lives in gets refactored by someone who doesn't know the rule is load-bearing.
Honesty note: preservation is the motion most easily skipped, because "I kept the existing rules" is the default-assumed answer. The Close-Out checklist forces the question to be answered in one of two explicit forms —
pinned(anchor+test+contract)ornone-this-cycle(<named scan with verb and target>)— and the verifier fails closed on hand-wave strings. Without that mechanical shape, preservation collapses back to a prose reminder, which is exactly the failure mode it is designed to prevent.
The Pattern
Every journey has the same root cause:
AI optimizes for the current request, not the long-term health of the codebase.
This isn't a defect — it's the nature of a stateless, memoryless system. The solution isn't to make AI "think deeper." The solution is to give it an environment where the correct choice is the default choice.
That's Archon Protocol: an operating system that turns AI's locally-optimal decisions into globally-consistent engineering output.
| Without Archon | 6 Months Later | With Archon |
|---|---|---|
| Files bloat until someone notices | Single file at 2000 lines; refactoring costs more than rewriting | Proactively detects bloat and splits |
| Patterns drift across sessions | 5 paradigms coexist; 3-day onboarding for new developers | Constraints lock validated patterns |
| Yesterday's decisions are forgotten | Same debates re-litigated every week | Manifest persistently carries decisions |
| Copy-paste until bugs spread | Bug fix in one copy, 3 copies still broken | Rule of Three triggers abstraction |
| Error handling is page-by-page lottery | Users encounter 4 different error UX styles | Knowledge evolution enforces consistency |
| Tests are optional until they're not | 16 endpoints, zero tests, zero confidence to refactor | Delivery hygiene flags + milestone gate blocks |
| New tech adopted without a manual | Each session re-learns the framework from scratch | Adoption skills ship with the technology |
| Code ships without documentation | Product works, but no one can explain how | Manifest + drift detection keep docs in sync |
| AI codes before thinking | Half-baked deliveries that need "undo and redo with a plan" | Verdict gate forces decomposition before first line of code |
| No architectural reasoning | 7 inline implementations of the same cross-cutting concern | Cognitive loop models subsystem boundaries before acting |
| Optimization only when humans complain | 4-second page loads discovered in production | Reviewer continuously audits performance across deliveries |
| Same mistake repeated every session | One-word bugs fixed 3 times in a week | Knowledge evolution crystallizes lessons into permanent constraints |
| Dev standards written but not followed | CONTRIBUTING.md ignored after first task | Constraint pyramid promotes rules to strongest enforceable level |
| Product terms lost every session | AI guesses "覆面卡" = back-card? side-card? burns tokens reconstructing meaning | Manifest glossary boots shared vocabulary; AI proactively aligns terms both directions |
| Load-bearing rules silently drained by refactors | Six-month-old guard disappears from a "cleanup" commit; bugs it prevented slowly return | Preservation Axis pins every load-bearing rule as anchor + body-shape test + portable contract (ADR-28) |